数据采集
数仓基础理论
做一个数仓的项目最先要做的是什么?
- 采用什么模型去设计
- 概念模型,逻辑模型怎么去划定
- 物理模型怎么设计
数仓的几种模型:星型模型,雪花模型,星座模型
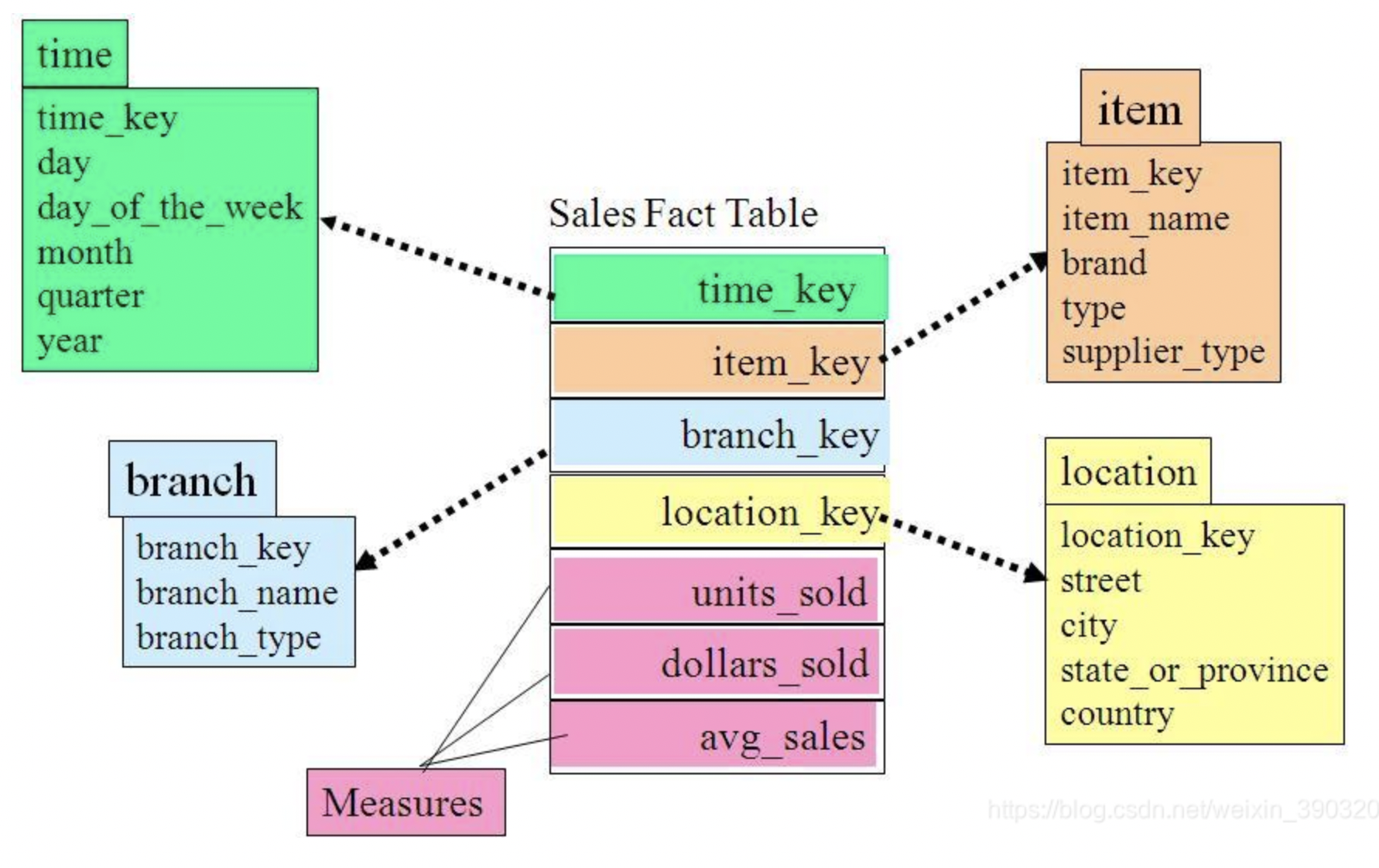
- 星型模型
星型模型主要是维表和事实表,以事实表为中心,所有维度直接关联在事实表上,呈星型分布。
模型的样式会比较固定,事实表的使用频次会特别高
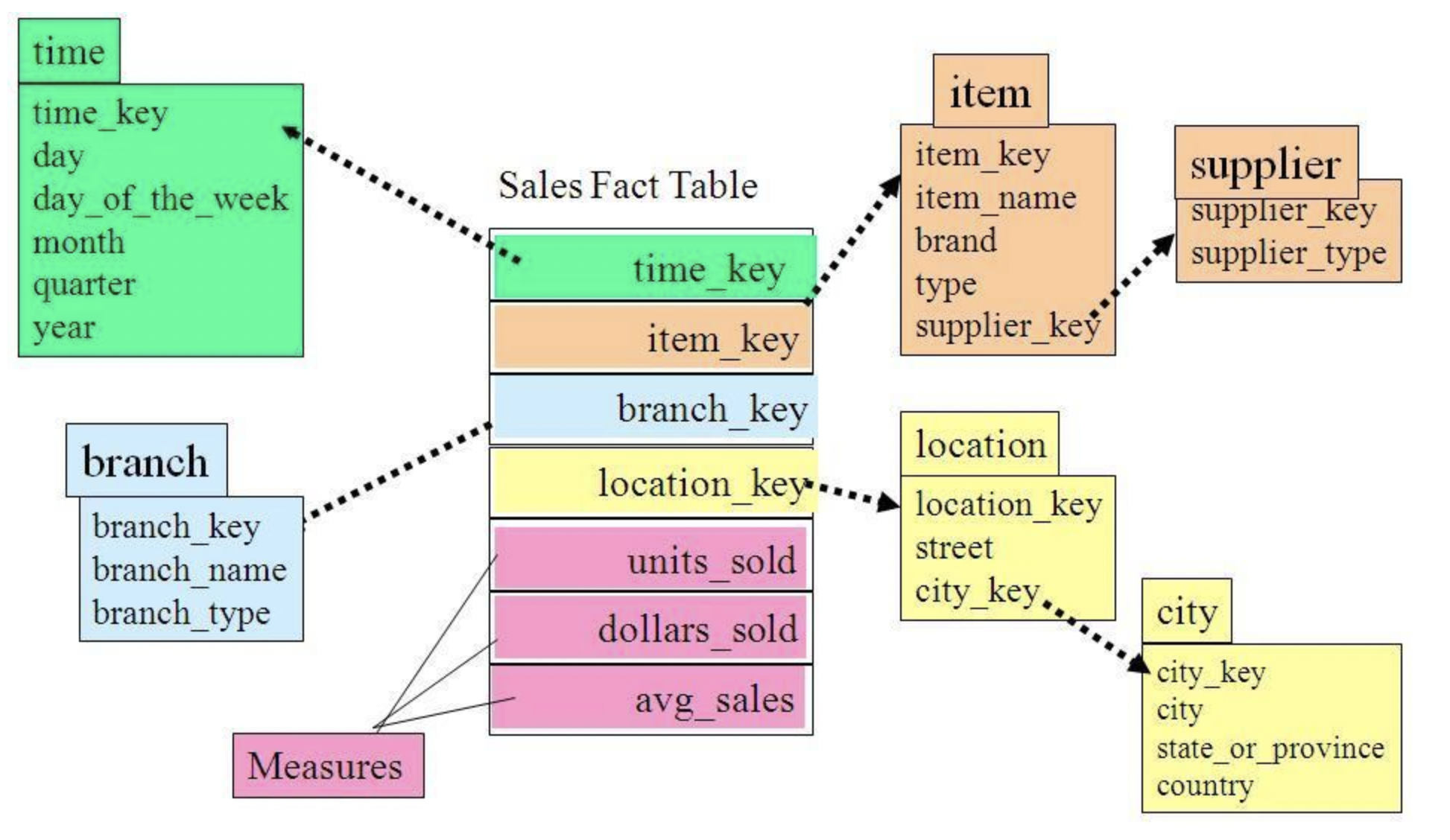
- 雪花模型
雪花模型,在星型模型的基础上,维度表上又关联了其他维度表。星型模型可以理解为,一个事实表关联多个维度表,雪花模型可以理解为一个事实表关联多个维度表,维度表再关联维度表。
可以理解为星型模型过滤到雪花模型
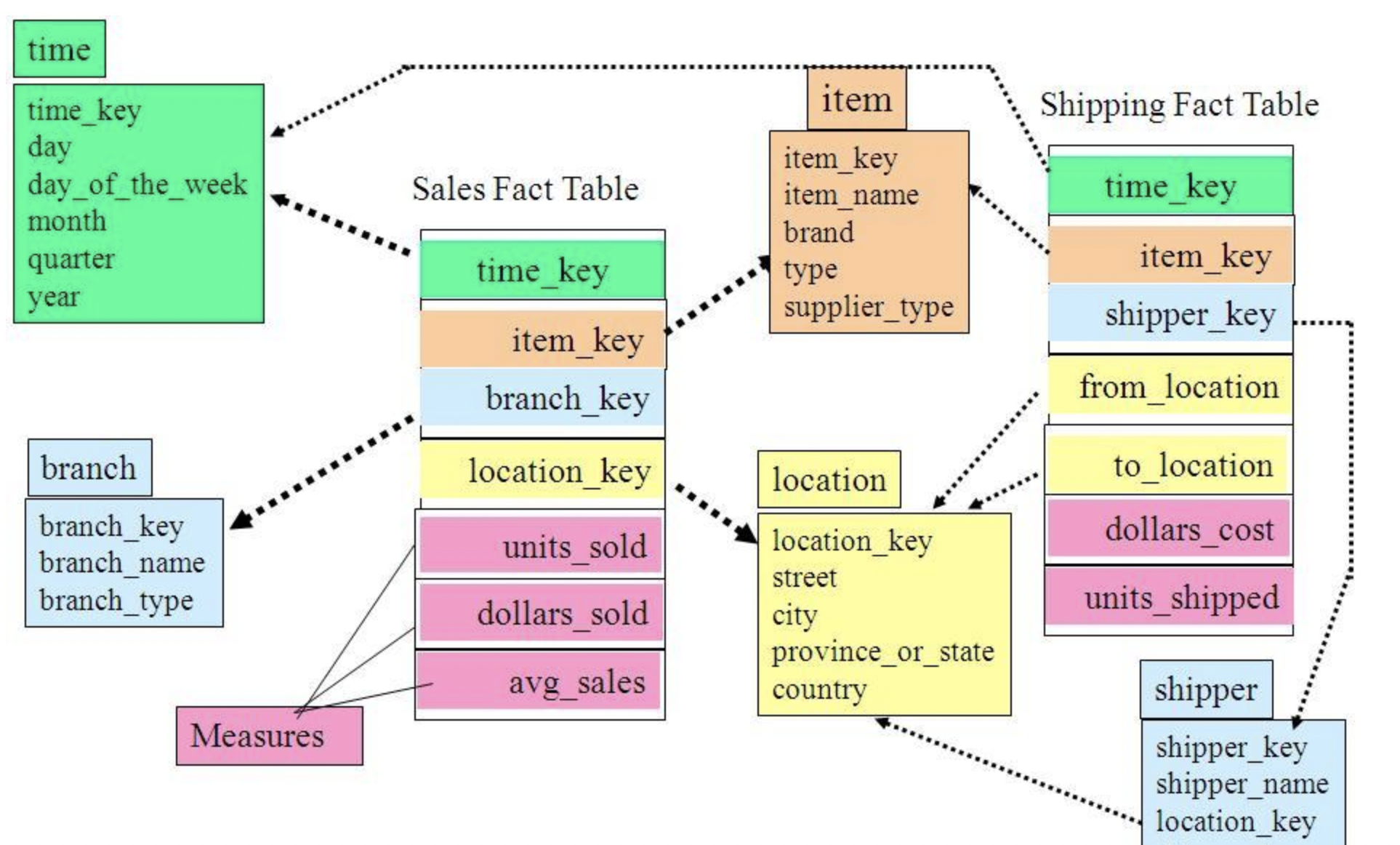
- 星座模型
用户画像是以星座模型为主的
星座模型,是对星型模型的扩展延伸,多张事实表共享维度表。
星座模型是很多数据仓库的常态,因为很多数据仓库都是多个事实表的。所以星座模型只反映是否有多个事实表,他们之间是否共享一些维度表。
用户画像逻辑模型设计
这个就是数据域的设计
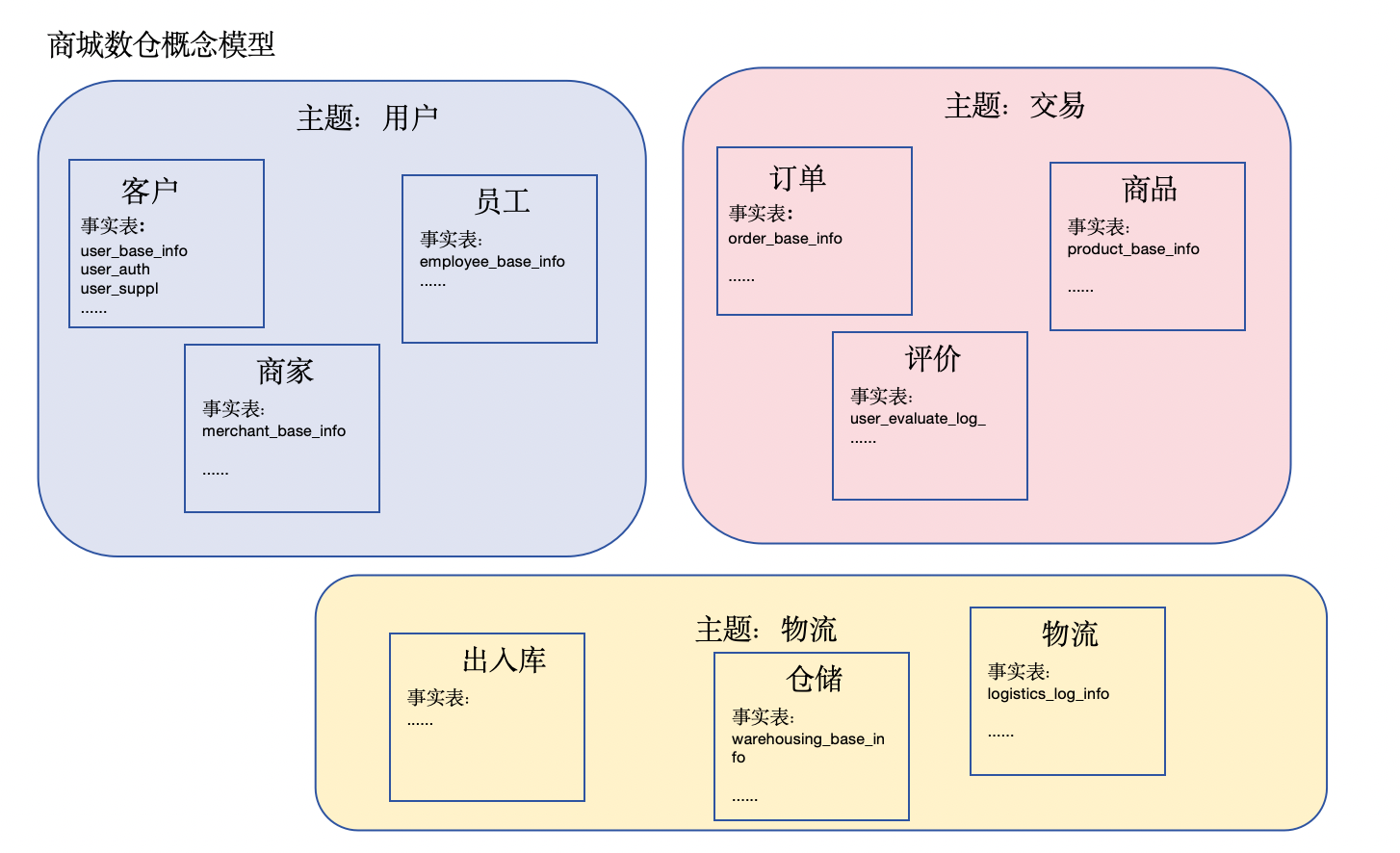
商城业务逻辑模型
借贷业务逻辑模型
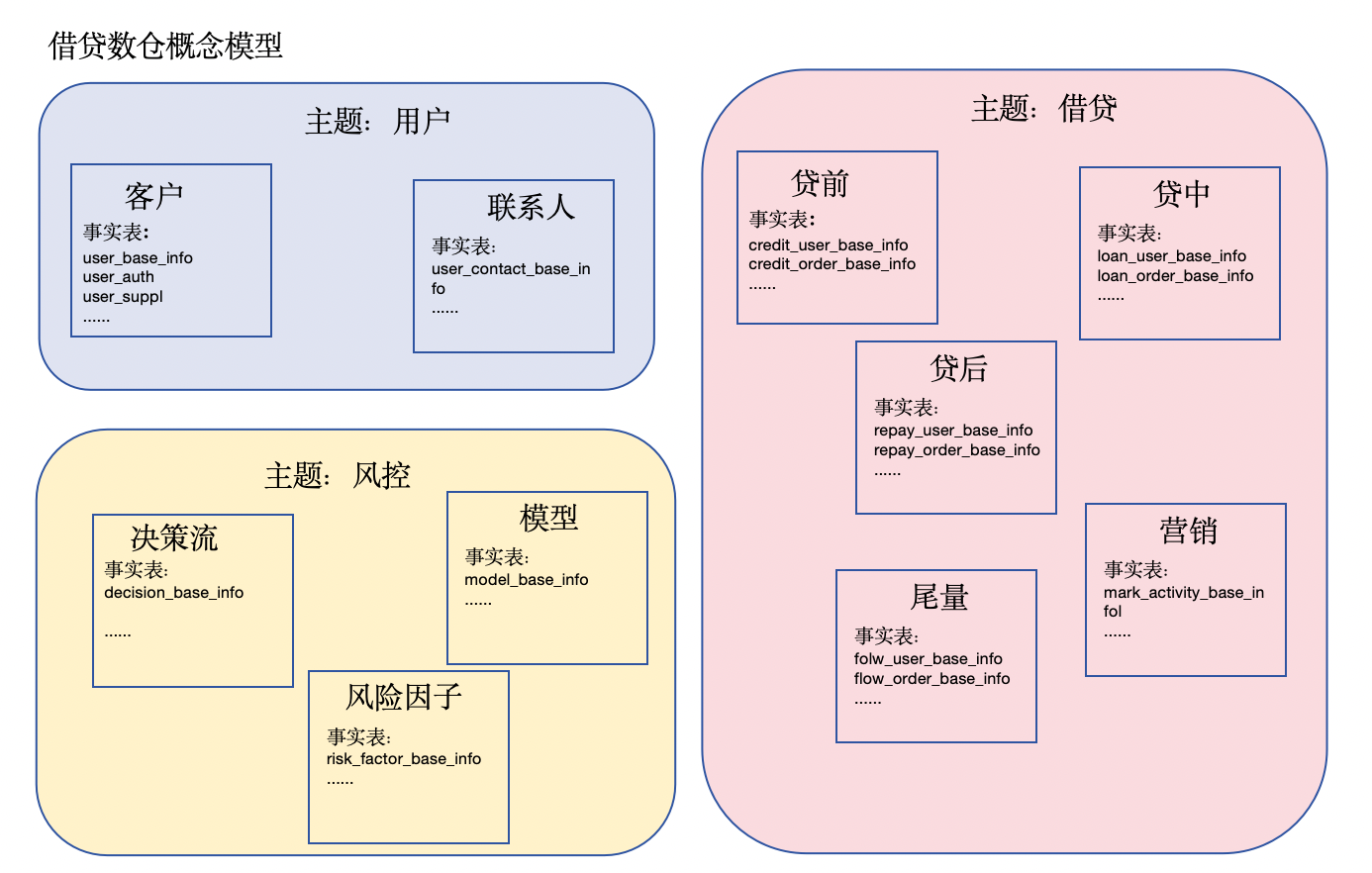
首先人去借款,去用户主题下面,然后用户会进行借款,进行贷前的行为,先进行风控决策里面进行判断这个用户是否可借款,借款额度是多少什么的,年化利率必须是多少,然后反馈到客户,客户如果能接收就发起申请,到了贷中内,然后就会走到贷后,贷后就是各种还款计划等等,有些用户发起了贷前走到了风控,我们发现这个用户的风险程度很高,我们会把这个用户卖给其他公司,让其他公司做,这个就叫做尾量,这里就是我们赚差价的钱。营销的话是识别有些用户有借款想法但是没有借款就使用营销把意向用户变成用户
用户画像表的设计
stg这个层是因为量级太大的话我们经常使用的是增量采集,然后增量数据和全量数据进行full join
stg里面我们现在放的是日增量,用ods表去full join这个stg的表去获取全量的数据
| 项目 | 库名 | 表名 | 主题域 | 描述 |
|---|---|---|---|---|
| 商城 | stg,ods | ods_user_base_info_d | 客户 | 客户基本信息表 |
| 商城 | stg,ods | ods_user_auth_info_d | 客户 | 客户实名信息表 |
| 商城 | stg,ods | ods_user_suppl_info_d | 客户 | 客户补充信息表 |
| 商城 | ods | ods_employee_base_info_d | 员工 | 员工基本信息表 |
| 商城 | ods | ods_merchant_base_info_d | 商家 | 商家基本信息表 |
| 商城 | ods | ods_order_base_info_d | 订单 | 订单基本信息表 |
| 商城 | ods | ods_product_base_info_d | 商品 | 商品基本信息表 |
| 商城 | ods | ods_user_evaluate_log_d | 评价 | 商品评价日志表 |
| 商城 | ods | ods_logistics_log_info_d | 物流 | 物流信息表 |
| 商城 | ods | ods_warehousing_base_info_d | 仓储 | 仓储信息表 |
| … | ||||
| 借贷 | ods | ods_user_base_info_d | 客户 | 客户基本信息表 |
| 借贷 | ods | ods_user_auth_info_d | 客户 | 客户实名信息表 |
| 借贷 | ods | ods_user_suppl_info_d | 客户 | 客户补充信息表 |
| 借贷 | ods | ods_user_contact_base_info_d | 联系人 | 联系人基本信息表 |
| 借贷 | ods | ods_credit_user_base_info_d | 贷前 | 贷前用户信息表 |
| 借贷 | ods | ods_credit_order_base_info_d | 贷前 | 贷前订单信息表 |
| 借贷 | ods | ods_loan_user_base_info_d | 贷中 | 贷中用户信息表 |
| 借贷 | ods | ods_loan_order_base_info_d | 贷中 | 贷中订单信息表 |
| 借贷 | ods | ods_repay_user_base_info_d | 贷后 | 贷后用户信息表 |
| 借贷 | ods | ods_repay_order_base_info_d | 贷后 | 贷后订单信息表 |
| 借贷 | ods | ods_flow_user_base_info_d | 尾量 | 尾量用户信息表 |
| 借贷 | ods | ods_flow_order_base_info_d | 尾量 | 尾量订单信息表 |
| 借贷 | ods | ods_decision_base_info_d | 决策流 | 决策流信息表 |
| 借贷 | ods | ods_model_base_info_d | 模型 | 模型结果表 |
| 借贷 | ods | ods_risk_factor_base_info_d | 风险因子 | 风险因子信息表 |
| … | ||||
| 流量数仓 | ods | ods_h5_event_i | h5埋点 | h5埋点信息采集表 |
| 流量数仓 | ods | ods_business_event_i | 业务埋点 | 业务埋点信息采集表 |
| … | ||||
| 三方采买 | ods | ods_third_{third_name}__i | 外部三方 | 外部三方采买数据表 |
| … | ||||
用户画像采集方式
一般阿里使用的dataX更多,sqoop已经不更新了,但是sqoop会更加的稳定
sqoop:
- 数据量大–Sqoop的性能在处理大量数据时可能受到限制,因为它使用MapReduce,而MapReduce的批处理性质可能导致较长的传输延迟。
- Sqoop是Apache Hadoop生态系统的一部分,专门用于在Hadoop和关系型数据库之间传输数据。它支持将数据从关系型数据库(如MySQL、Oracle、SQL Server)导入到Hadoop中,也支持将数据从Hadoop导出到关系型数据库。
- 可接受高并发的模式
sqoop采集是最常用的一种形式 import是将数据写入到hdfs列
1 | sqoop import \ |
这里的一些内容进行如下解释:
–hive-partition-value ${1}
作用: 定义 Hive 表的分区值。
例子:
如果 ${1} 是传入的分区值,比如日期 2024-11-21,则 Hive 表会按分区存储数据,路径为:
1
/user/hive/warehouse/mall.db/ods_user_base_info_d/dt=2024-11-21/
数据会写入分区字段 dt 的值为 2024-11-21 的分区中。
–fields-terminated-by “\0001”
作用: 定义字段之间的分隔符。
例子:
在导入数据到 Hive 表时,每行的字段用 \u0001(不可见字符)分隔。例如:
1
1\u00012024-11-21\u0001John\u0001Doe'
这样 Hive 能正确解析字段。
–lines-terminated-by “\n”
作用: 定义行的分隔符。
例子:
数据文件中的每一行是以换行符 \n 结束的。例如:
1
21\u00012024-11-21\u0001John\u0001Doe\n
2\u00012024-11-22\u0001Jane\u0001Doe\n–input-null-string 和 –input-null-non-string
作用:
保证 MySQL 和 Hive 之间对于 NULL 值的处理一致。
–input-null-string: 用于处理 字符串类型的 NULL 值。
–input-null-non-string: 用于处理 非字符串类型的 NULL 值。
例子:
MySQL 中:
id name age 1 NULL 25 2 John NULL Hive 中:
1 | 1\u0001\N\u000125 |
NULL 值会被转换为 \N,以便 Hive 正确识别。
这里有一些需要注意的点:
- 一般我们query中的sql中的字段顺序需要和我们写入到hive表对应列的顺序相同
- 我们在设置了
hive-overwrite -m这个设置也就是并发数量的设置,如果不是1的话我们必须要设置下面的split-by设置,因为是这样的,sqoop并发的话需要一个并发字段,首先假如我们这里设置的并发数量是4,看我们这里设置的并发字段是id,就会根据id先去排序,然后根据排序平均划分4份,然后把这平均划分的四份分散到4个不同的线程去执行并发,如果设置了并发但是不写并发字段的话sqoop就不知道用哪个字段做并发就会报错
传输到mysql,使用比较少
1 | sqoop export |
这个就是eval的脚本测试的时候用
1 | sqoop eval |
1、sqoop的默认并发数是4 - m 1. 每次采集数据的一个量级
2、sqoop数据倾斜问题 - m 10 60min. split by KEY (int) 100000/10 10000 0-10000 10000+100000/10 ;KEY
这个数据倾斜的问题大概率是这个split by key中的这个key的问题,key最好是int类型
3、sqoop底层执行的是什么任务 mr map-m 10 reduc-0
只有map任务,没有reduce
DataX:
- DataX是阿里巴巴开源的数据交换工具,不仅支持Hadoop生态系统,还支持其他各种数据存储和处理系统,如关系型数据库、NoSQL数据库、Hive、HBase等。
- DataX支持多种读写插件,可以更好地处理不同数据源和目标的性能需求,从而提供更高的灵活性和性能。
- 全内存操作,不读写磁盘,对大数据量的处理上存在内存限制的问题
包装到shell里的一个命令:
Data_shell.sh
1 | source ~/.bashrc |
json的内容:
1 | { |
Seatunnel基本介绍
详情查看博客中seatunnel中的内容
Flat file:
- 注意这张表的格式 是一个JSON格式的表,可以做到直接将一个json字段的key映射为表中的字段
1 | CREATE EXTERNAL TABLE `ods.ods_third_{third_name}_i`( |
表结构
1 | --商城用户信息表 |