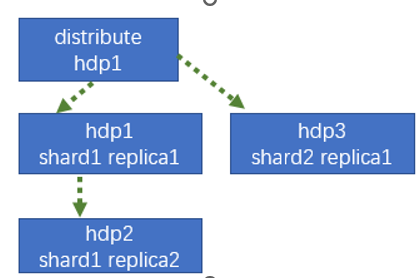
clickhouse的副本和分片
clickhouse的高可用也就是这个副本
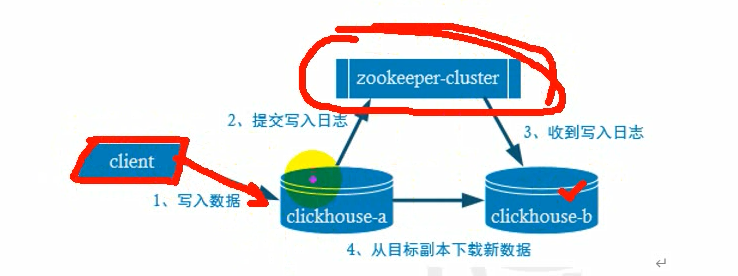
副本写入流程

zk里面的日志是几月几号接收了什么数据,相当于一个流水账
配置更改
我们首先要有两台以上机器,都启动ck和zk
然后更改
在这个里面搜搜zookeeper,如果有就更改,没有的话就新增如下内容:
创建上面的文件,然后
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>bigdata01</host>
<port>2181</port>
</node>
<node index="2">
<host>bigdata02</host>
<port>2181</port>
</node>
<node index="3">
<host>bigdata03</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
|
我们需要在两个机器上面创建表
1
2
3
4
5
6
7
8
9
10
| create table rep_t_order_mt_1214 (
uid UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt_1214','rep_hdp1')
partition by toYYYYMMDD(create_time)
primary key (uid)
order by (uid ,sku_id );
|
1
2
3
4
5
6
7
8
9
10
| create table rep_t_order_mt_1214 (
uid UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/01/rep_t_order_mt_1214','rep_hdp2')
partition by toYYYYMMDD(create_time)
primary key (uid)
order by (uid ,sku_id );
|
这里的ReplicatedMergeTree就是创建一个副本的表,前面传入的是一个路径,不是文件系统的路径,而是zookeeper上面日志的路径;后面传入的是副本名称,虽然表一样,路径必须相同,但是副本名称不能相同
ReplicatedMergeTree这个merge是自带幂等性的,为了防止数据复制的时候重试的操作造成数据重复,如果两次sql是相同的,那么第二次的sql就不会执行,保持幂等性
分片集群
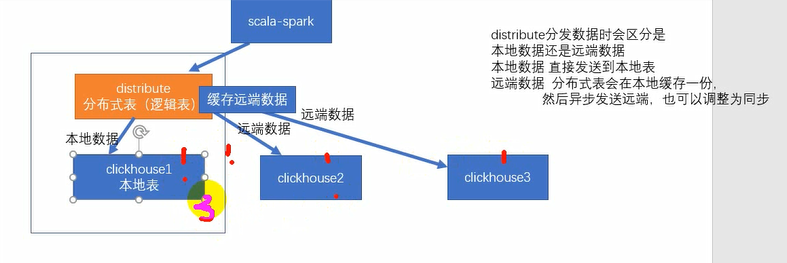
如何让很多台机器处理一条数据呢就是分片集群
目前的这个架构是首先会有一个分布式的表,这个分布式的表,分布数据的时候会区分本地数据还是远端数据,如果是本地数据的话就直接发送给本地数据那份,如果是远端数据,那么我们会进行异步操作,首先会先在本地缓存一下需要同步到远端的数据内容,然后再告诉客户端已经完成了,然后再异步的将这个远端的数据从本地发送过去,因为数据传输也需要时间,所以就是异步的传输远端数据了
但是这种方式虽然可以扩展性能,但是不能进行高可用了,因为只要有一块数据丢了就相当于数据缺失了
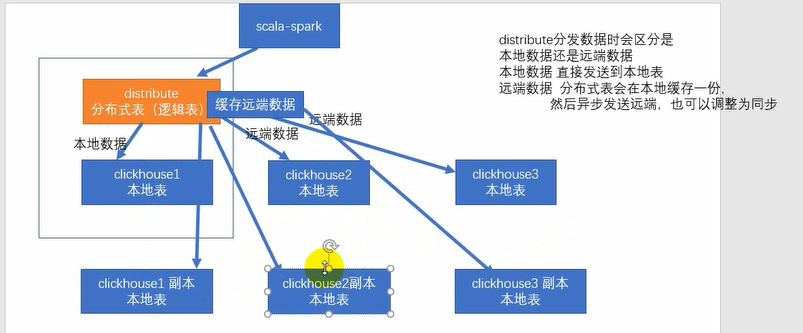
如果再加一份机器的话就可以既做远端,又可以做副本同步高可用
推荐这种方式,不通过分布式表发送6份,而是本地进行副本
查询的时候分布式表再把每份分片的结果进行拼接
三节点版本配置
需要在config.xml ,中找到remote_servers 标签, 补充
1
| <remote_servers incl="clickhouse_remote_servers">
|
在config.xml中加入
1
2
| <zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika-shards.xml</include_from>
|
metrika-shards.xml 的配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| <yandex>
<clickhouse_remote_servers>
<gmall_cluster>
<shard>
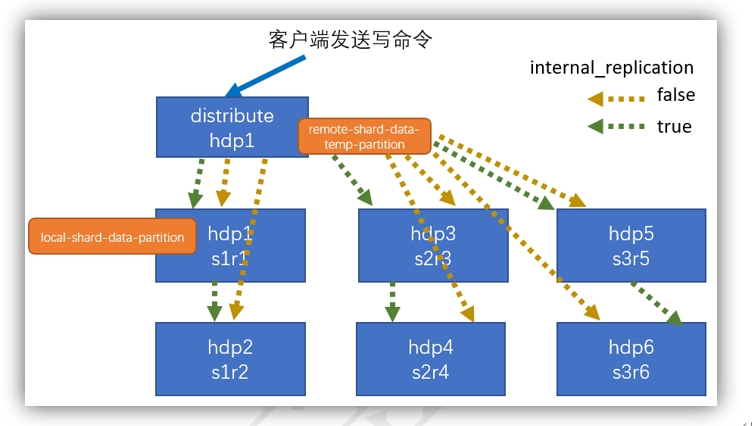
<internal_replication>true</internal_replication>
<replica>
<host>hdp1</host>
<port>9000</port>
</replica>
<replica>
<host>hdp2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>hdp3</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard>
<replica>rep_1_1</replica>
</macros>
</yandex>
|
这个配置是对于上面的配置文件中的配置
| hdp1 |
hdp2 |
hdp3 |
<macros> |
<macros> |
<macros> |
<shard>01</shard> |
<shard>01</shard> |
<shard>02</shard> |
<replica>rep_1_1</replica> |
<replica>rep_1_2</replica> |
<replica>rep_2_1</replica> |
</macros> |
</macros> |
</macros> |
创建本地表
1
2
3
4
5
6
7
8
9
10
| create table st_order_mt_1214 on cluster gmall_cluster (
uid UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt_1214','{replica}')
partition by toYYYYMMDD(create_time)
primary key (uid)
order by (uid ,sku_id );
|
这里写的on cluster gmall_cluster是会把这个建表语句发给其他的集群,这里的{shard}和{replica}对应上面配置文件中的内容,写这个就会从本地的配置文件中找到这个值替换进去
创建分布式表
1
2
3
4
5
6
7
| create table st_order_mt_1214_all on cluster gmall_cluster
(
uid UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
)engine = Distributed(gmall_cluster,up2021, st_order_mt_1214,hiveHash(sku_id))
|
其中参数:
Distributed( 集群名称,库名,本地表名,分片键)
分片键必须是整型数字
也可以rand()
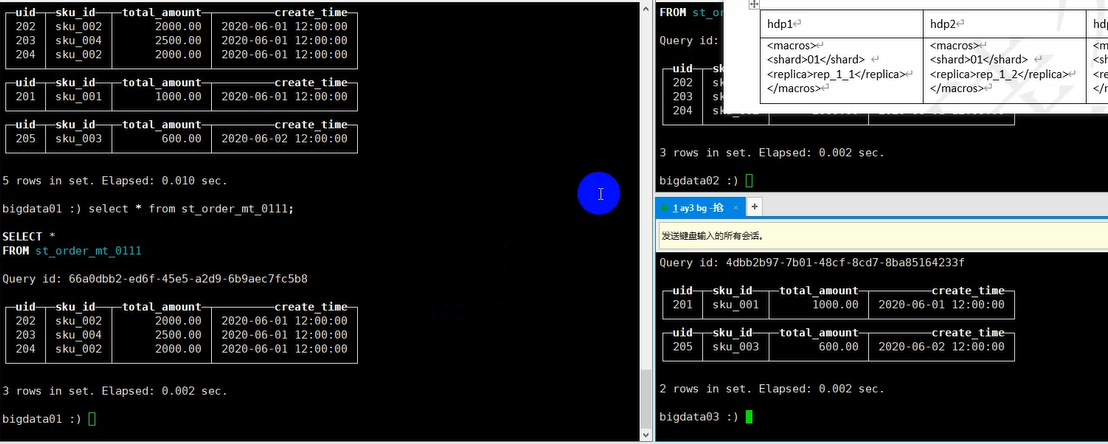
向其中一台机器的分布式表插入数据:
1
2
3
4
5
6
7
| insert into st_order_mt_1214_all
values(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00')
(205,'sku_003',600.00,'2020-06-02 12:00:00')
|
查询一下各个机器上的本地表中的数据,发现已经将分布式表中数据分散到三台机器中了