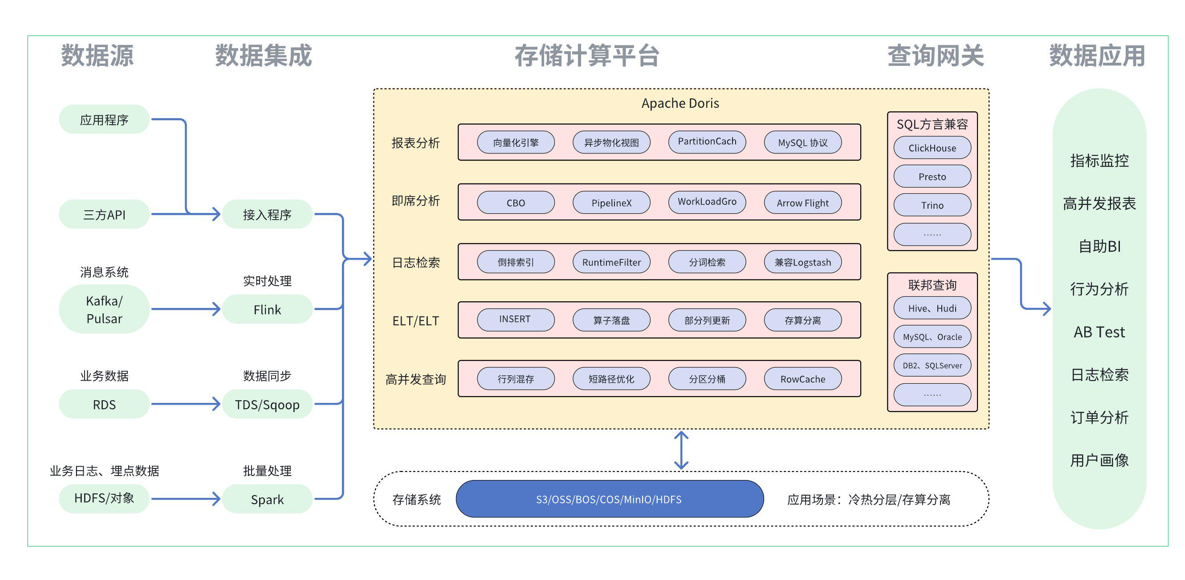
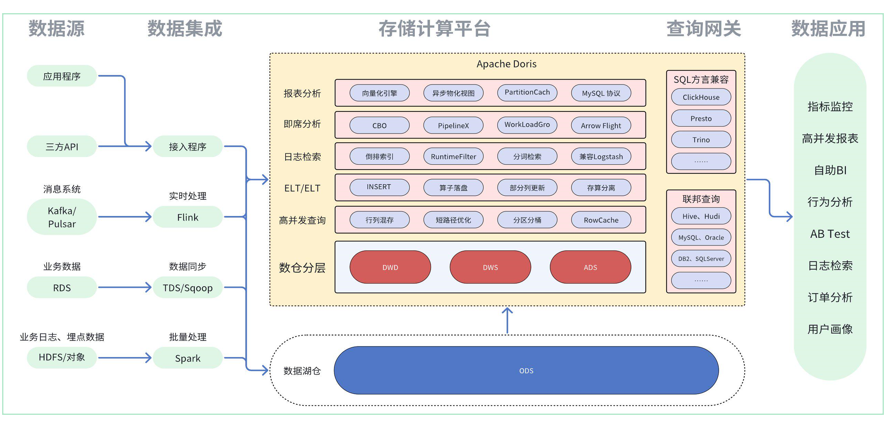
doris3.0特性
Doris 3.0 面向云原生的湖仓一体解决方案
从存算一体到存算分离
之前版本的doris的架构师存算一体的架构,部署简单,仅仅是fe和be的进程,FE和BE都可以单独扩容,并且不依赖其他的共享存储系统,计算节点也可以直接访问本地存储不占用带宽资源
那么我们为什么要进行存算分离呢?
有以下几点原因:
首先低成本和资源弹性:
- 计算和存储的资源解绑了,可以单独对一部分进行扩容
- 根据计算资源更好的能分辨出哪些是使用资源多的可以更好的区分开冷热数据,进行设置冷热数据
- 可以计算出资源的波峰和波谷
负载隔离:
- 读写任务隔离
- 彻底的业务隔离
数据共享
- 单一数据可以面对不同的分析任务负载使用
- 数据可以快速移动,更快速的备份和恢复,因为计算和存储已经分开了
云设备成熟
- 可以将存储上云了
存算分离架构
元数据服务层
3.0的fe还是保持元数据服务层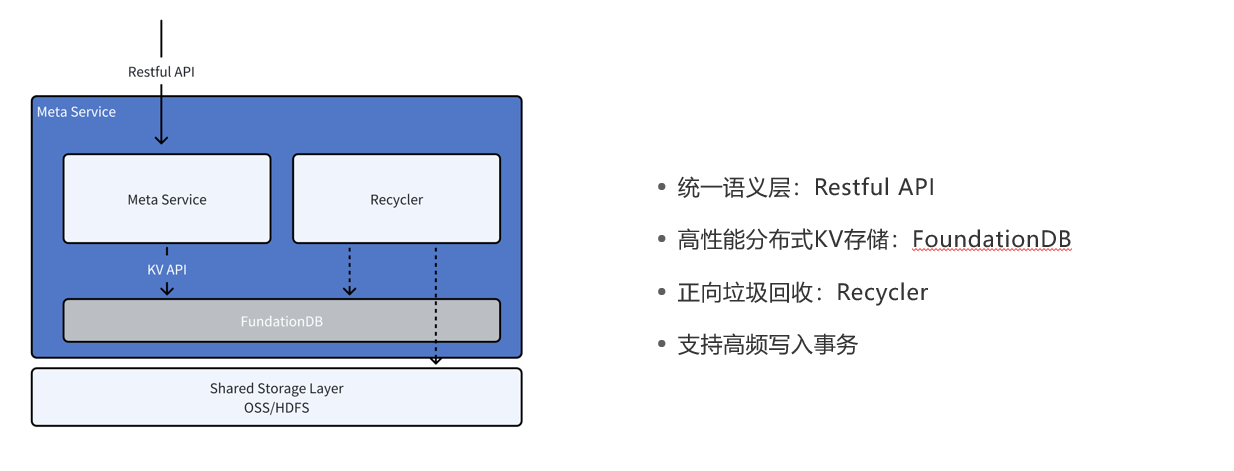
数据存储层
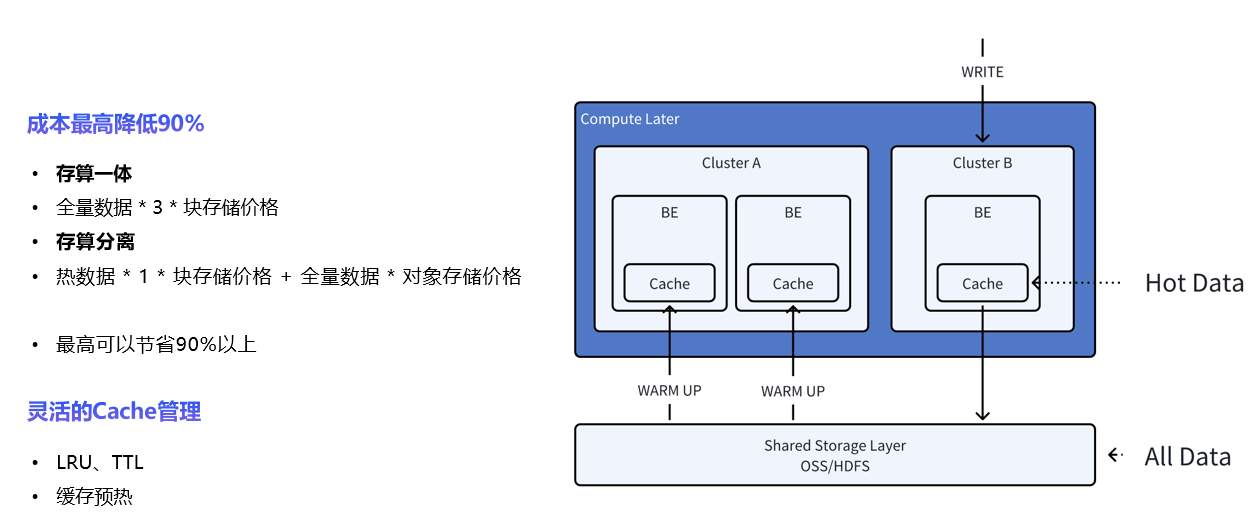
数据存储层3.0的版本可以更加的节省成本,主要是能够更好的分隔开热存储和冷存储,具体的成本降低多少可以查看图片
并且对我们存储的热数据可以进行更好的缓存管理,使用了LRU(一种缓存策略),TTL,缓存预热
LRU
这里我们介绍一下LRU,LRU是一种维护了一个数据访问的队列,当数据被访问了就会将这个数据移动到队列的前端,新加入缓存的数据也会移动到队列的前端,当缓存达到上限,队列尾部的数据会被删除
TTL
TTL策略是为了保护我们喜欢在本地可以持久化的一些小规模的数据表,对于常驻表我们可以使用设置较长的TTL来保护这个表当缓存空间不足的时候会先淘汰其他数据,设置了TTL的数据先不动
使用方法:
在建表的时候可以设置对应的property,该表的数据使用ttl策略进行缓存
1 | CREATE TABLE IF NOT EXISTS customer ( |
这里的配置是设置了缓存时间300s,如果在建表的时候没有指定ttl,我们也可以设置ALTER语句来修改ttl属性
1 | ALTER TABLE customer set ("file_cache_ttl_seconds"="3000"); |
缓存预热
存算分离下,doris可以多个计算组进行配置,但是如果新的计算组创建的时候缓存为空,就可能会影响到查询性能。Doris各个计算组内共享数据但是不共享缓存,于是doris支持了缓存预热,可以直接从远端存储主动拉取数据到本地缓存
举例说明:
假设在 Doris 中存储了大量的销售数据,每天会进行多次查询分析,以了解某商品的销量趋势和每日交易情况。以下是没有缓存预热和使用缓存预热的对比:
没有缓存预热的情况:
查询发起后,Doris 需要从存储层读取商品的每日销量数据,这个过程包含磁盘 I/O 操作,耗时较长。
用户可能需要等待几秒甚至几分钟,尤其是当数据量非常大时,等待时间会更长。
使用缓存预热的情况:
每天凌晨(或其他查询量较低的时段),您可以通过预热将前一天的销售数据加载到 Doris 的缓存中。
当早上用户查询时,Doris 可以直接从缓存中读取数据,无需进行磁盘 I/O,查询速度会快很多。
因为缓存中已经有需要的数据,响应时间可以降低到几毫秒到几秒,大大提升了用户的查询体验
使用方法:
目前支持三种缓存预热,下面只介绍最常用的两种:
将表 customer 的数据预热到 将表 customer 的数据预热到 compute_group_name1。
执行以下 SQL,可以将该表在远端存储上的数据全部拉取到本地。这里的compute_group_name1是计算组的名字,我们可以执行
SHOW COMPUTE GROUPS;来查看有哪些计算分组1
WARM UP COMPUTE GROUP compute_group_name1 WITH TABLE customer
将表 customer 的分区 p1 的数据预热到 compute_group_name1。
执行以下 SQL,可以将该分区在远端存储上的数据全部拉取到本地。
1
WARM UP COMPUTE GROUP compute_group_name1 WITH TABLE customer PARTITION p1;
这里的预热,可以把sql中的预热记为这个WARM UP
上面的sql会返回一个job id,也就是预热任务的id,我们可以查询预热进度
1 | SHOW WARM UP JOB WHERE ID = 1234; |
数据计算层
之前的版本中,doris的副本数量是取决于独立ip的个数,但是目前的3.0版本将doris的存储与计算分隔开了,存储可以存储在hdfs或者云端,所以现在数据导入只需要处理单副本数据就可以了,速度更快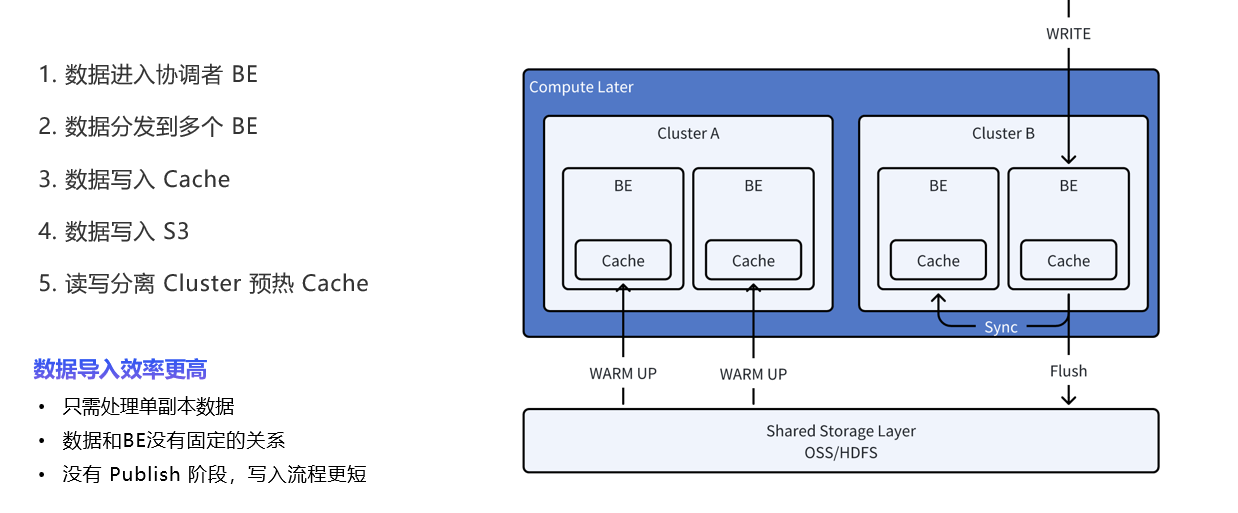
doris的存算分离的最佳实践
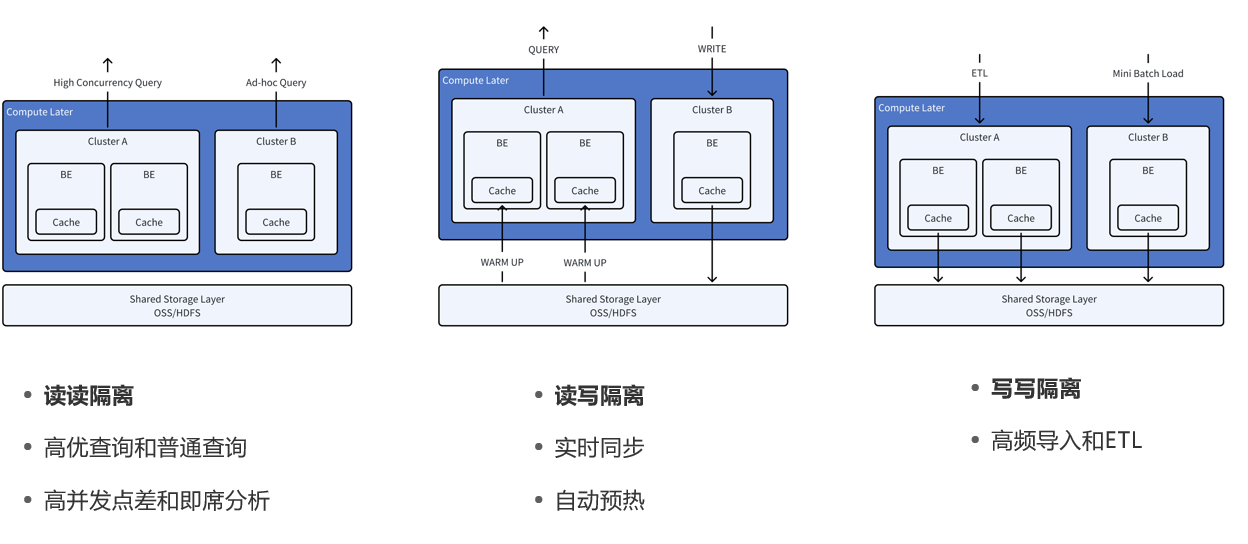
下面我详细介绍一下这三种存算分离的机制
在业务上这三种是我们经常使用的机制,由于doris3.0存算分离我们可以将不同的业务场景的计算分隔开都同时写入到一个存储系统中,各个业务场景互不影响更加的高效,更好的资源分隔
读读隔离
用途:用于高并发查询和普通查询的隔离。
架构:
计算层(Compute Layer):包含多个计算集群(Cluster A和Cluster B),每个集群中有多个后端节点(BE)和缓存(Cache)。
共享存储层(Shared Storage Layer):底层存储使用OSS(对象存储服务)或HDFS(Hadoop分布式文件系统),存储数据以支持计算层的查询请求。
工作流程:
高并发查询和普通查询被分配到不同的集群中,如Cluster A用于高并发查询,Cluster B用于普通查询。
这种分离使得高并发查询和普通查询的资源使用互不干扰,从而提高查询的响应速度和效率。
优势:
实现了高优查询和普通查询的隔离,提高了系统的并发能力。
高并发场景下,能够优化数据访问路径并减少资源争用。
读写隔离
用途:实现查询和写入操作的隔离。
架构:
计算层同样由两个集群组成(Cluster A和Cluster B),底层的共享存储使用OSS或HDFS。
工作流程:
写入操作分配到Cluster B,而查询操作分配到Cluster A。
数据从存储层加载到各个集群时,会通过预热机制(Warm Up)使得数据提前缓存到内存中,提高读取效率。
优势:
查询和写入操作的隔离避免了写入对查询性能的影响。
预热机制保证了查询时的数据访问速度,使得查询效率进一步提升。
支持实时同步和自动预热,适合需要实时响应的业务场景。
写写隔离
用途:支持高频数据导入和ETL(数据提取、转换和加载)操作的隔离。
架构:
两个集群(Cluster A和Cluster B)分别用于不同的写入操作。
共享存储层同样是OSS或HDFS。
工作流程:
Cluster A用于ETL操作,即将数据从外部数据源提取、转换后加载到系统中。
Cluster B用于批量数据导入(Mini Batch Load),适合高频数据的批量导入。
优势:
写写隔离确保了ETL和高频数据导入不会相互影响,提高了数据导入的效率。
这种分离方式支持同时进行的多种写入操作,特别适合数据更新频繁的场景。
总结
存算分离:所有场景下,计算层和存储层都是分离的。共享存储层可以支持不同的计算集群进行读写操作。
缓存机制:每个集群都有缓存模块,缓存可以显著提高查询的响应速度。
不同的隔离方式:根据实际业务需求,采用读读隔离、读写隔离和写写隔离策略,实现不同业务场景的优化。
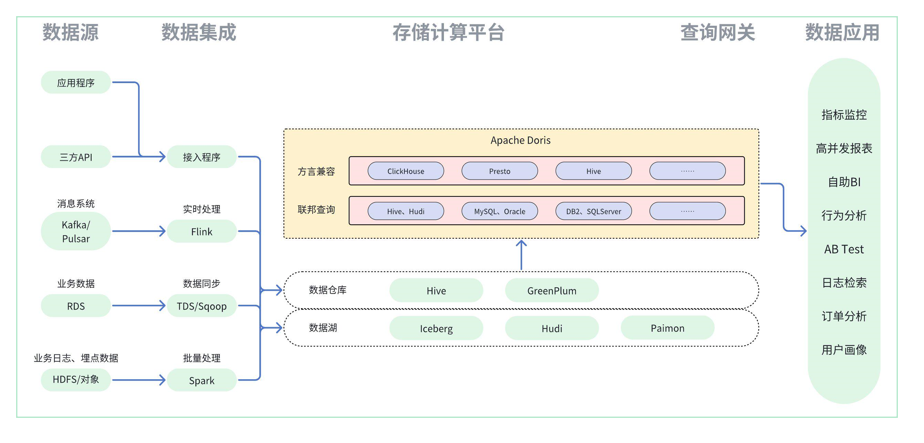
基于doris构建湖仓一体化的体系
湖仓一体建设方案
数据湖透明加速方案
湖仓一体化构建过程中,在不影响现有业务运行稳定性下,往往只需要通过引入 Apache Doris 做 OLAP 数据查询加速引擎即可完成对数据湖数据的查询加速,主要实现方案为:
1.利用联邦查询和SQL方言兼容特性,对外构建提供服务的统一查询网关能力,对内构建管控所有异源数据的汇集能力,由内至外实现百川入海。
2.利用数据湖 Catalog 能力完成数据查询透明加速能力,以 Hive 为例,先获取 HMS 元数据信息,通过 SQL 解析后将 Doris-SQL 信息转化为 HMS 信息,获取实际 Parquet、Orc 等格式文件的实际存储地址,将文件直接读取加载至 Doris 计算节点内存中,利用向量化引擎、PipelineX等特性完成加速查询,同时还可借助 ComputerNode 节点能力隔离出独享计算资源完成计算,不影响其他业务的正常运行。
3.若有频繁查询的结果集,可利用 PartitionCache 将结果集和原始数据缓存至 Doris 集群中,后续再有相关查询即无需通过网络 IO 做二次传输,可加速查询效率。
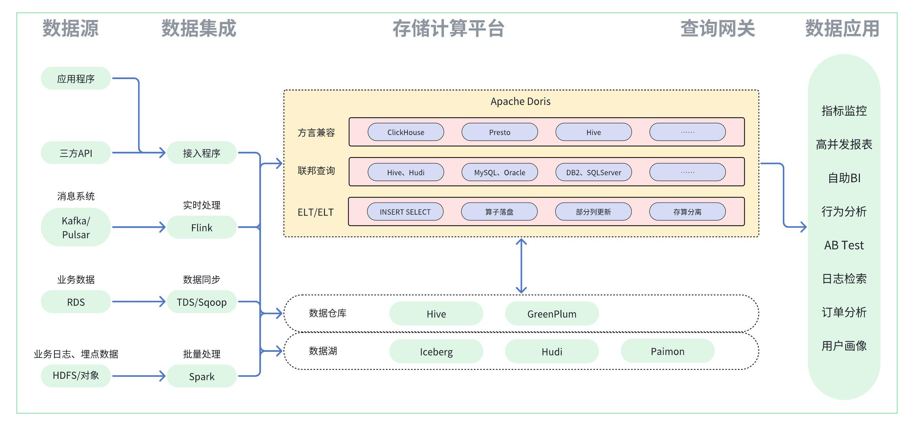
通过众多 Doris 用户生产实践反馈得知,在同等数据量、同等查询任务、同等机器资源量以及同等查询并发度的情况下,Doris 跑批任务速度比 Hive 快 8-10 倍,比 Spark 快 2-3 倍。该效率归功于向量化引擎、PipelineX、CBO、智能化分区分桶等各种黑科技的加持。
在上述场景的收益比下,湖仓一体化构建方案中还可以借助 Doris 强大的跑批性能完成批任务的加速执行:
1.通过 Catalog 湖仓联邦能力,可将原有执行任务切换至 Doris 执行,通过 Doris 透明加速能力,完成结果集计算,若有其他维表关联或者异源数据关联计算诉求,可不通过数据同步的方案来具备关联计算的基础条件,直接通过联邦查询能力即可完成,减少数据同步任务的开发量和跑批任务的复杂度。
2.当前 Doris 已支持 Hive 数据湖的回写能力,可通过 Doris 完成 Hive 数据湖的计算后,将结果集回写至 Hive 数仓中供其他业务线共享使用。
3.切入一部分新实时业务或者离线实时化改造业务直接写入 Doris 实时数仓完成实时业务构建。
在部分企业实践过程中,比较关注数据的存储成本,往往 Doris 内仅存储过往半年或者一年内的数据,更往前的历史数据都希望在较为低廉的存储系统中进行存储,或者进行科学计算场景的应用。
但是在上述诉求下,还希望继续通过 Doris 完成整体的查询,比如季度报表、年度报表等数据,不要求查询效率和内表一样快速,但是要求在业务使用时不再进行查询语句上大幅度的改变,最好是能自动冷备,数据还不冗余存储,查询时可自动路由,那基于上述要求可如下完成方案思路设计:
1.若希望自动冷热分层至 S3 或者 HDFS 等数据湖存储介质上,可利用 Doris 的冷热分层特性来满足,创建存储介质的 Resource 后,通过给表绑定 Resource 资源,指定 ColdDownTime 或者 TTL 时间,使其自动完成冷备。该方案在查询时无需额外操作,Doris 会自动路由远端数据加载至内存,与热数据一起完成计算。
若希望历史数据可参与共享计算,完成科学学习计算等场景的应用,可通过回写 Hive 或者 Export 至 HDFS/S3 上,导出为 Parquet、Orc 等公共格式,参与其他场景的共享计算。在查询时,可通过 TVF 或者 Catalog 关联完成数据加载计算。
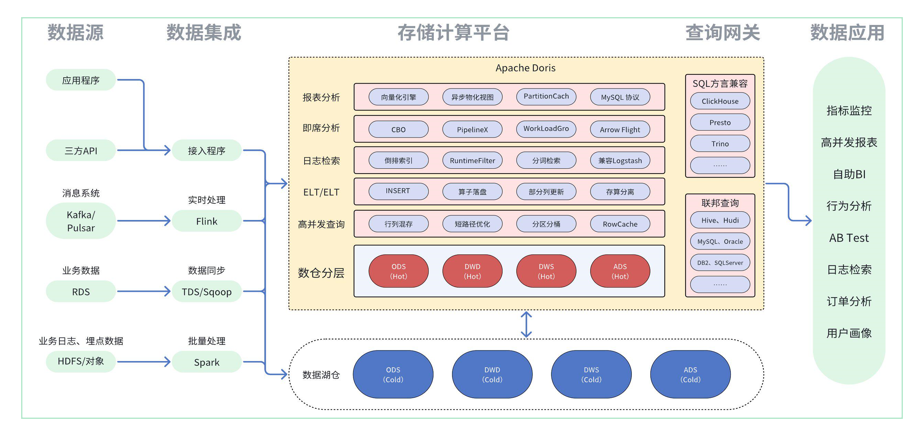
在湖仓一体化分层构建方案中,主要有贴源层数据共享使用的诉求,即数据湖是统一数据入口,所有原始明细数据都在数据湖组件中留存一份,其他数据仓库和数据科学计算或者应用都基于该数据完成计算:
1.利用 Doris 的 Catalog 能力将数据湖中 ODS 层数据根据分层加工逻辑,通过调度任务能力或者异步物化视图能力加工为 DW 层数据,并将该层数据落盘至 Doris 内表中。
2.后续通过加工完的 DW 层数据在 Doris 集群内部实现上层数仓构建,可依赖异步物化视图的构建或者任意支持 MySQL 协议的调度平台进行加工,或者使用 DBT 等 ELT 工具来完成上层数仓构建。
前缀索引和倒排索引
在搜索doris相关内容的时候发现了doris的倒排索引,虽然不是新特性,是2.0版本的特性,但是还是在这里记一下吧
复习一下之前doris的前缀索引的内容,
首先我们在doris中设置了三种聚合模型 Aggregate、Unique 和 Duplicate 。底层的数据存储,是按照各自建表语句中,Aggregate Key、Unique Key 和 Duplicate Key 中指定的列进行排序存储的,我们根据排序键指定查询条件就不用扫全表就可以找到需要处理的数据,在这基础上又引入了前缀索引,前缀索引可以全量在内存缓存,快速定位数据块,大大提升了查询效率。前缀索引的设计是索引项不超过36个字节。
当遇到 VARCHAR 类型时,前缀索引会直接截断。如果第一列即为 VARCHAR,那么即使没有达到 36 字节,也会直接截断
所以varchar类型最好放在后面
比方说我们设计的表的结构是如下这样的: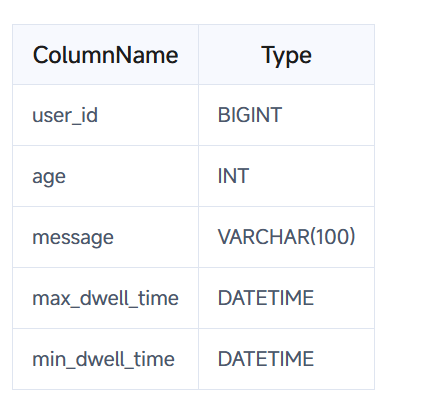
那么前缀索引为:user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
如果我们设计的表结构是这样的:
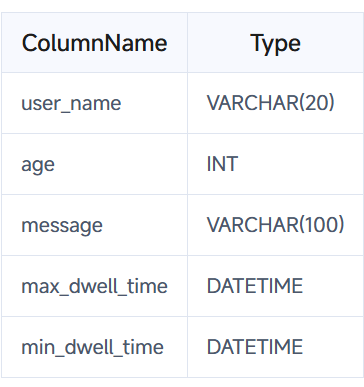
则前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
如果我们前面设计的表结构有问题了,我们要更改查询的顺序我们就应该设计rollup上卷或者物化视图,具体方法在doris学习笔记中
好的,说完前缀索引下面说倒排索引
首先需要说一下,这个前缀索引啊,rollup,物化视图啊和这个倒排索引有什么区别
首先倒排索引特别适用于文本数据或者需要精准匹配的字段,比如查找特定的字符串或者关键词搜索
rollup是针对表的特定维度进行预聚合,物化视图是根据复杂的查询逻辑进行预计算,适用于聚合查询比较多的场景,需要频繁计算某些统计指标
总结:
倒排索引:更适合查询条件中涉及大量过滤的场景,对特定字段的精确匹配查询性能提升明显。
Rollup/物化视图:适合聚合、汇总类的查询,可以显著提高复杂查询的性能,但适用的查询类型相对固定。
接着说回倒排索引
倒排索引可以加速等值、范围、全文检索(关键词匹配、短语系列匹配等)。一个表可以有多个倒排索引,查询时多个倒排索引的条件可以任意组合。
使用语法:
1 | CREATE TABLE table_name |
下面的properties是可选的,是倒排索引的额外属性,目前支持的属性包括指定分词,中文分词,英文分词,指定细粒度的分词还是粗粒度的分词,指定是否支持短语查询加速,指定在分词之前是否对短语文本进行预处理,比如替换调某一个字符,是否对分词进行大小写转换,是否忽略一些停用词,这里具体配置可以查看https://doris.apache.org/zh-CN/docs/table-design/index/inverted-index/
给已有的表增加倒排索引:
1 | -- 语法 1 |
这两种语法都可以支持创建倒排索引
在给已经有的表增加了倒排索引之后,我们要对存量数据也添加倒排索引
1 | -- 语法 1,默认给全表的所有分区 BUILD INDEX |
那么我们怎么使用倒排索引来进行加速查询呢,详细见下面的示例:
1 | -- 1. 全文检索关键词匹配,通过 MATCH_ANY MATCH_ALL 完成 |
如果我们要检查一下分词的实际效果或者只是对一段文本有一次的分词行为,那么我们就可以使用分词函数TOKENIZE来测试
TOKENIZE 函数的第一个参数是待分词的文本,第二个参数是创建索引指定的分词参数。
1 | mysql> SELECT TOKENIZE('武汉长江大桥','"parser"="chinese","parser_mode"="fine_grained"'); |
具体还有更加详细的案例在官网上,对于更加详细的案例就不做过多介绍,详见官网,下面附上官网文档地址