seatunnel学习笔记(三)
应用案例
kafka进出的简单etl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| env{
execution.parallelism = 1
}
source{
KafkaTableStream{
consumer.bootstrap.servers = "data1:9092"
consumer.group.id = "test"
topic = seatunnel_test
result_table_name = test
format = csv
schema = "[{\"field\":\"name\",\"type\":\"string\"},{\"field\":\"age\", \"type\": \"int\"}]"
format.field-delimiter = "," # 字段分隔符,根据;进行切分
format.allow-comments = "true" # 允许注释行
format.ignore.parse-errors = "true" # 忽略解析错误,当出现解析错误的时候,忽略该条数据向下进行解析
}
}
transform{
sql{
sql = "select name,age from test where age > '"${age}"'"
}
}
sink{
kafkaTable{
topics = "test_sink"
producer.bootstrap.servers = "data2:9092"
}
}
```shell
bin/start-seatunnel-flink.sh --config config/example03.conf -i age=18
|
kafka输出到doris做指标统计
我们首先需要在doris上创建一下表
1
2
3
4
5
6
7
8
9
10
11
12
13
| CREATE TABLE `example_user_video` (
`user_id` largeint(40) NOT NULL COMMENT "用户id",
`city` varchar(20) NOT NULL COMMENT "用户所在城市",
`age` smallint(6) NULL COMMENT "用户年龄",
`video_sum` bigint(20) SUM NULL DEFAULT "0" COMMENT "总观看视频数",
`max_duration_time` int(11) MAX NULL DEFAULT "0" COMMENT "用户最长会话时长",
`min_duration_time` int(11) MIN NULL DEFAULT "999999999" COMMENT "用户最小会话时长",
`last_session_date` datetime REPLACE NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次会话时间"
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `city`, `age`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
;
|
然后需要编写seatunnel的配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| env{
execution.parallelism = 1
}
source{
KafkaTableStream{
consumer.bootstrap.servers = "data1:9092"
consumer.group.id = "test"
topic = test
result_table_name = test
format.type = json
}
}
transform{
sql{
sql = "select user_id,city,user_age as age,video_count as video_sum,duration_time as max_duration_time,duration_time as min_duration_time,session_end_time as last_session_date from test"
result_table_name = test2
}
}
sink{
DorisSink{
source_table_name = test2
fenodes = "data3:8030"
database =test_db
table = example_user_video
user = root
password = "12138
batch_siza = 50
doris.colum_separator = "\t"
doris.columns="user_id,city,age,video_sum,max_duration_time,min_duration_time,last_session_date"
}
}
|
扩展(代码贡献开源社区)
开源社区主要有三个身份标签
- contributor:贡献者
- committer:提交者
- PMC:管理者
贡献代码过程
创建issue

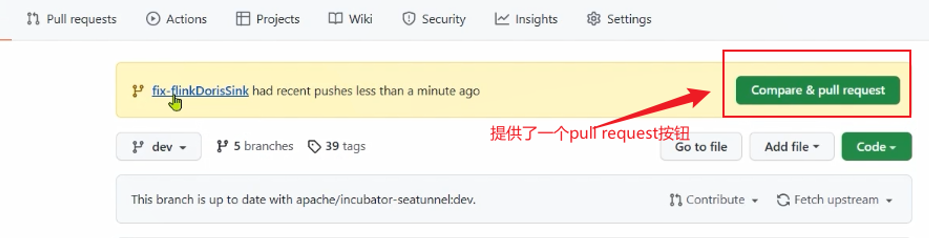
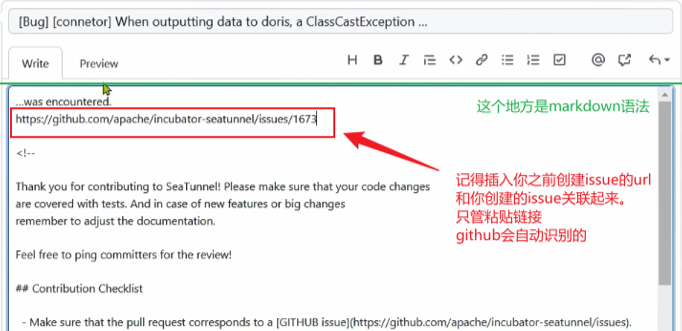
创建pull request
也就是发出改过代码的拉取请求
首先需要先fork官方的仓库,拉取到我们自己的仓库中,然后git clone自己fork的这个仓库,然后在本地修改代码,然后push到我们fork的这个仓库中
创建pr
这个时候我们可以发现,可以创建pr了
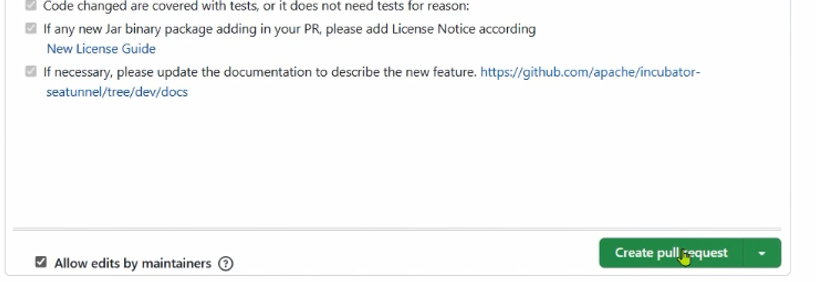
等待测试通过,测试通过后可能会进行合并
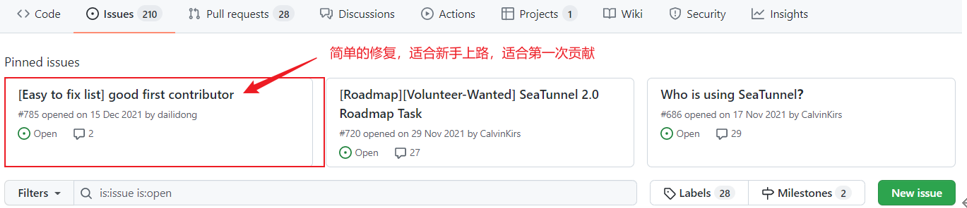
寻找机会
一般apache的开源项目会维护一个待办列表,列表中是一些好做的任务,适合新手上路
我们可以尝试做一下这里面的任务来学习获取贡献者的身份