redis基础学习(一)
基本介绍
功能
分布式缓存:redis的数据操作主要在内存,是kv数据库的一种
内存存储和持久化,redis异步将内存数据写到磁盘上
高可用架构:单机,主从,哨兵,集群
缓存击穿,雪崩,击穿
分布式锁
队列
排行+点赞
优势
- 性能高
- 数据类型丰富
- redis支持数据持久化,内存中数据保存到磁盘,重启的时候再次加载使用
- redis支持数据备份

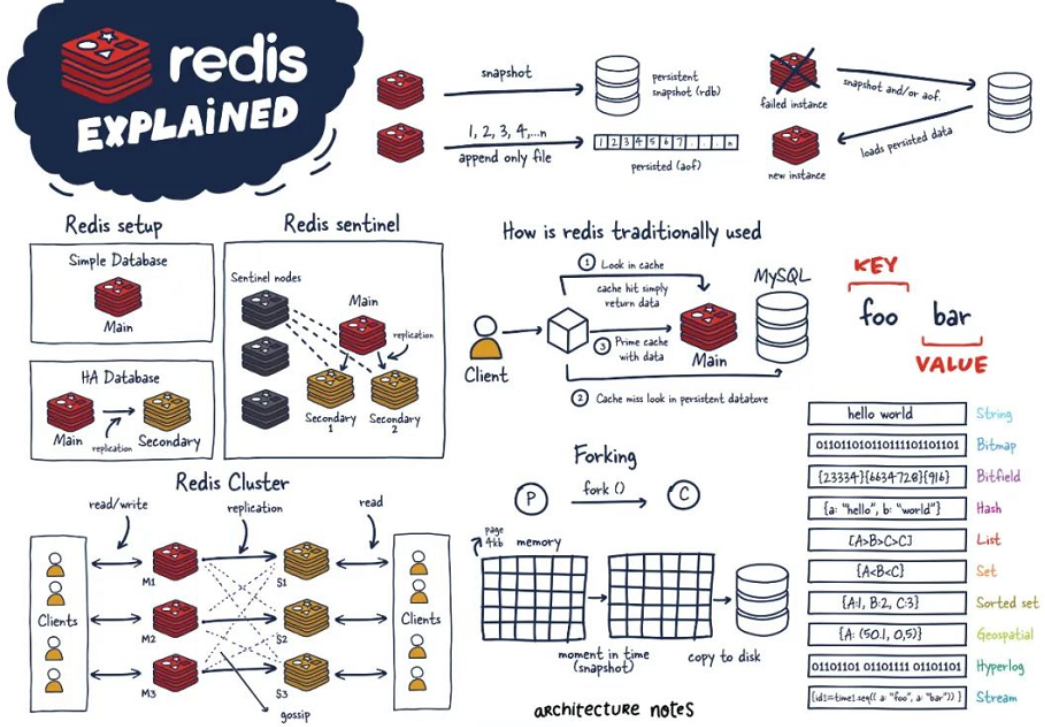
redis的十大数据类型
string
list:双端链表
hash
set:集合,通过哈希表实现,集合中不能出现重复数据
zset:有序集合,每个元素关联一个double类型的分数,通过分数进行排序
GEO:地理信息:
添加地理位置的坐标。 获取地理位置的坐标。 计算两个位置之间的距离。 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合HyperLogLog:基数统计,在redis中,每个HyperLogLog只需要花费12kb的内存,元素越多,耗费的内存却是很小的,但是不会存储元素本身,只会根据输入的元素来计算基数
bitmap:位图 0和1 表现的二进制的bit数组
bitfield:位域,一次性对多个比特域进行操作
Stream:流
常见操作

redis数据类型使用
这里现用现查
redis的持久化机制
防止内存中的数据丢失
备份和恢复
数据迁移
RDB
全量快照,实现把某一时刻的数据和状态写道磁盘中
优点
适合大规模的数据恢复,对业务定时备份,对数据完整性和一致性要求不高的场景,RDB文件在内存加载速度比AOF快很多
缺点
每隔一段时间机械能一次备份,如果redis死掉,就会丢失当前到最近一次快照期间的数据,快照数据会丢失
内存数据全量同步,使用资源太大
什么时候会触发RDB快照
- 配置文件中的配置
- 手动save保存
- 主从复制,主节点触发
- 执行shutdown适合没有设置开启AOF持久化
AOF
日志的形式来记录所有的写操作,只记录写操作,重启就按照写操作的命令重新执行一次
默认是不开启AOF的
AOF持久化工作流程
请求命令会先写到一个AOF缓存中保存,然后根据配置的AOF缓存策略再写入到AOF文件,服务器重启适合会从AOF文件载入数据
AOF缓存写入策略
- Always:每条命令都写入AOF缓存中,然后同步到磁盘。性能影响大
- Everysec:每秒写入。可能丢失一秒数据
- No:操作系统控制写入。可能丢失很多数据
优点
性能高可以做紧急恢复
缺点
AOF文件比RDB文件大,恢复速度慢
AOF运行效率比RDB慢
RDB+AOF的混合持久化
使用RDB做全量快照,AOF做增量备份
先用RDB做全量快照存储,AOF持久化记录所有的写操作,当重写策略满足的适合,将最新的数据存储为新的RDB。重启服务的适合就会从RDB和AOF两部分恢复数据
纯缓存模式
建议不要
关闭RDB和AOF
redis事务
事务中所有的命令都会序列化,顺序的执行,不会被其他命令插入
redis的事务和传统数据库的事务不同,不一定是一起成功或者一起失败
redis管道
如何优化频繁命令往返带来的性能瓶颈
这个问题是由于redis发送命令是这样的:
首先发送命令,然后命令排队,命令再执行,执行后返回一个结果应答,然后下一条命令再执行,这样中间就来回的应答频繁io
这里就可以使用redis的管道
概况
pipeline是将命令打包一次性发送
pipeline支持批量执行不同的命令
管道和事务对比
事务有原子性,管道没有原子性
管道是一次性发送多条命令,事务是一条一条发送
事务会堵塞其他命令,管道不会
redis复制
主从复制:master以写为主,slave以读为主
master数据变化的时候,会将新数据异步同步到slave数据库
支持什么
- 读写分离
- 容灾恢复
- 数据备份
- 水平扩容
使用
只需要配置从数据库,不需要配置主数据库
复制原理
从数据库首次启动会连接主数据库与进行一次全量复制,slave原有的数据会覆盖
master收到要复制的命令会先RDB一个快照,同时手机所有的修改数据集的命令缓存,然后把RDB文件和这些命令都给从数据库
master10秒和slave进行一次心跳检测
master继续将修改命令发给slave
redis哨兵模式
检查后台的maser死没死,死掉就投票换一个从数据库
首先某个slave被选为新的master,规则是:
在配置文件中的,按照优先级进行选举,复制偏移量offset最大的从节点
然然后其他节点变成他的从节点,就算老节点恢复了,也变成从节点
redis集群
数据量过大,单个master没法支撑,所以要组成集群
集群模式支持多个master,每个master下面还有多个
集群模式自带故障转移,所以不需要再配置哨兵模式
集群算法
redis的集群分配是根据槽位来分配的
分槽和分片:
这种分槽和分片很适用于扩容和数据分片查找
Hash槽= CRC16(KEY) % 16384
redis单线程和多线程
redis其实整体来看是多线程的,但是redis的持久化RDB或者AOF,异步删除,集群数据同步,这些都是额外的线程来执行的,命令的工作是单线程的
老版本的redis是单线程的,新版本是多线程的
redis单线程的问题
大key:如果一个key特别大,那么删除key的时候就会堵塞
redis的多线程特性和IO多路复用
redis的主要瓶颈就是内存,网络IO
redis现在版本的多线程就是来处理网络请求的,多IO线程来处理网络请求,但是读写操作还是单线程来处理
IO多路复用:
I/O多路复用,就是通过一种机制,让一个线程可以监视多个链接描述符,一旦某个描述符就绪(一般都是读就绪或者写就绪),就能够通知程序进行相应的读写操作。这种机制的使用需要select 、 poll 、 epoll 来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
它的概念是:多个Socket链接复用一根网线,这个功能是在内核+驱动层实现的。
redis的Morekey问题
Morekey会让查询或者删除都做的很慢
优化:在配置里面使用惰性释放
也就是多线程来异步删除数据
redis的一致性
缓存双写一致性
如果redis有数据就需要和数据库的值相同
如果redis没有数据,数据库中如果是最新值就要回写到redis中
缓存操作
只读缓存
读写缓存:
- 同步读写缓存
- 写数据库的同时也要写redis缓存,缓存和数据库中的数据一致
- 如果要缓存和数据库中的数据一致就要使用同步读写缓存
- 异步读写缓存
- 正常业务,如果mysql数据变动了,可以允许一定时间后作用到redis
- 异常情况出现,需要借助kafka等中间件来重写
双缓加锁
这个是为了防止多个线程同时查询相同的数据项,数据项步骤缓存中,所有线程都会查询数据库更新缓存.避免缓存穿透
多个线程同时去查数据库的这条数据,我们可以在第一个查询数据的请求上加一个互斥锁,其他线程到这一步拿不到锁就等着,等第一个线程查询到了数据然后做缓存,后面的线程进来发现有缓存了就走缓存
详细说明
- 第一次检查缓存:
每个线程首先检查缓存中是否存在所需的数据。
- 获取互斥锁:
如果缓存中没有数据,第一个线程获取互斥锁,防止其他线程同时查询数据库。
- 第二次检查缓存:
拿到锁的线程在查询数据库之前再检查一次缓存,以防其他线程在此期间已经更新了缓存。
- 查询数据库并更新缓存:
如果第二次检查缓存仍然没有数据,则查询数据库并更新缓存。
- 释放锁:
更新缓存后,释放互斥锁,其他线程可以继续获取数据。
1 | import java.util.Map; |
缓存检查:
每个线程在 getValue 方法中首先尝试从缓存中获取值:
1 |
|
获取锁:
如果缓存中没有数据,尝试获取锁:
1 |
|
使用 tryLock 方法避免线程在锁上无限等待,可以更优雅地处理并发。
第二次检查缓存:
在获取到锁后,第二次检查缓存:
1 |
|
查询数据库和更新缓存:
如果缓存仍然没有数据,则查询数据库并更新缓存:
1 |
|
释放锁:
更新缓存后,确保锁被释放:
1 |
|
等待和重试:
如果没有获得锁,等待一段时间后再次检查缓存:
1 |
|
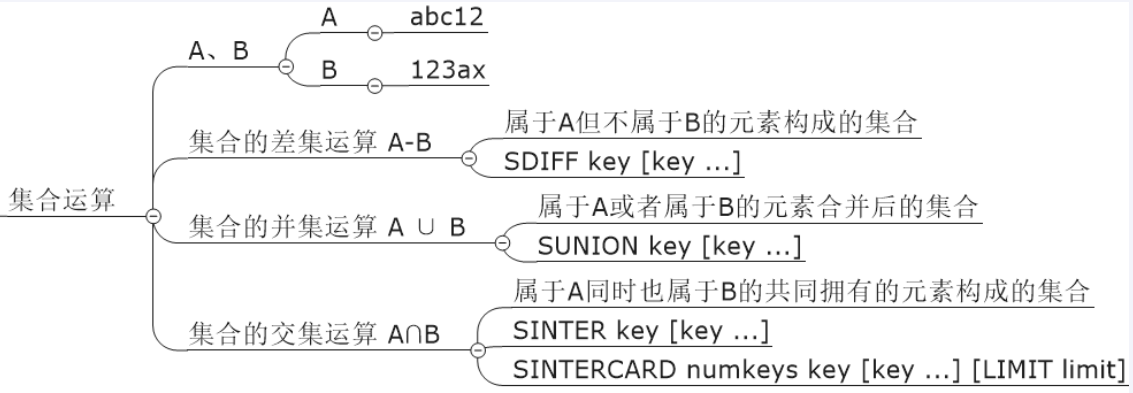
bitmap/hyperloglog/GEO
需求痛点:上亿级别的数据的收集清洗统计和展现
存的进,取得快,多维度
大数据量的常见的四种统计
聚合统计

排序统计
设计一个最新的列表或者排行榜的需求,数据更新频繁,并且需要分页
二值统计
只有0和1 两种,使用bitmap
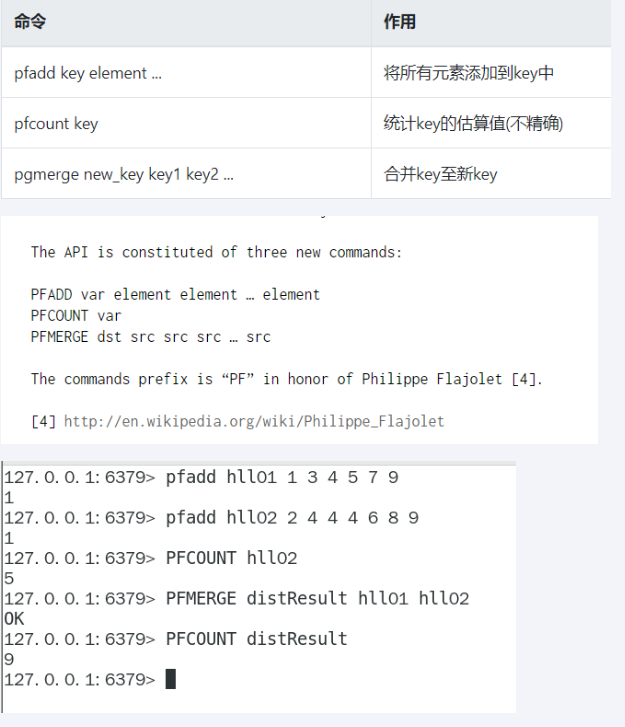
基数统计
使用hyperloglog
hyperloglog
获取去重后的真实数据的个数
GEO
可以添加经纬度坐标,然后计算两个位置之间的距离,或者以半径为中心,查找附近的
添加坐标
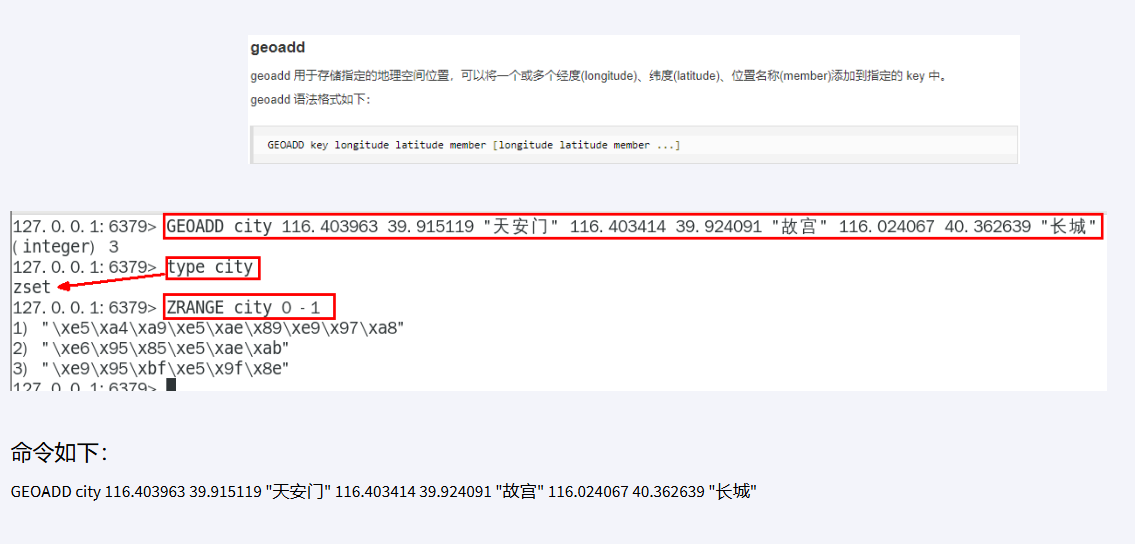
计算距离

查找附近的

bitmap
可以统计日活,连续签到打卡,最近一周的活跃用户,统计指定用户一年之中的登录天数
缓存预热+缓存雪崩+缓存击穿+缓存穿透
缓存预热
在系统启动的时候提前把常用的数据加载到缓存中,提高系统性能
缓存雪崩
redis主机挂了,全崩了或者是redis大量key同时过期
redis的key设置永远不过期
redis设置主从+哨兵
开启redis持久化AOF/RDB快速恢复集群
多缓预防雪崩
缓存穿透
简单来说这个事情出现有两种情况:
- 黑客攻击了
- mysql中没有数据,redis的缓存中也没有数据,大量查询这个数据的请求进来了,就会给数据库很大的压力
方案一:两次查询
- 首先是第一次查询在redis缓存中查询数据,发现没有命中,然后去mysql中查询数据,发现也没有命中
- 然后返回了一个null
- 将这个key和默认的defaultNull值写入到redis中
- 下一次的查询直接就在redis的缓存中查到了defaultNull,就不用查询数据库了,因为没有数
方案二:布隆过滤器
首先布隆过滤器是一个数据结构,可以用来判断一个元素是否在集合中
在查询缓存和数据库之前,使用布隆过滤器检查请求的键是否可能存在。如果布隆过滤器认为键不存在,直接返回默认值。
缓存击穿
大量的请求都查询一个key,这时候这个key正好失效了,大量的请求就会访问到数据库上
方案一:
一般业务部门知道哪些是热点的key,热点key就不设置过期时间了
方案二:
互斥锁,用互斥锁锁住,第一个拿到数据的就做缓存,后面的线程之间在缓存里面就取到了

reids为什么快
IO多路复用
IO多路复用要解决的问题是之前用一个进程来处理一个请求,这个太奢侈了,类似于一个学生配一个老师
IO:网络IO
多路:多个客户端连接,多个TCP
复用:一个进程处理多条连接,单线程就能实现多个客户端的连接
redis的IO多路复用为什么快
redis使用epoll来实现IO多路复用,把连接信息和事件放到队列,一起放到分派器,分派器再分发给事件处理器。这样一个进程来处理了大量的用户连接
redis的所有操作都是单线程的顺序执行,但是读写操作等待用户的输入输出都是杜塞的,IO操作一般不能直接返回,IO多路复用就是解决这个问题
同步和异步
这里扩展一下,之前看到的很有意思的一些名词解释
后续更新redis底层算法,redlock算法