常见问题总结(持续更新)
一致性保证数据不丢失,怎么保证数据一致性
- 开启事务
- 每条数据分配唯一标识,处理数据的时候检查是否处理相同的标识
- 数据审计和日志
- 实时监控数据结果,设置监控和报警
- 数据备份
- 数据治理
UV/PV/DAU/MAU
UV: 独立访客数,一天内访问过网站的访客数量,考虑去重
PV: 页面浏览量,一天内访问过网站的页面浏览量,不用去重
DAU: 独立用户数,一天内访问过网站的独立访客数量,考虑去重(日活跃用户量)
MAU: 独立用户数,一周内访问过网站的独立访客数量,考虑去重(月活跃用户量)
对实时仓库的数据监控,任务运行状态的监控,比如任务的健康度,数据质量和各个维度的监控异常的报警,应该怎么设计
数据监控和任务状态监控可以使用
kafka
flink
Promethus
Grafna
ELK
实时数据监控
- 数据完整性
- 数据准确性
- 数据及时性
- 数据一致性
可以在数据流处理的时候添加数据记录数,监控数据丢失或者重复
在数据流中添加时间戳字段,记录延迟时间
异常数据报警
数据内容异常:定义异常规则,实时监测记录异常
数据延迟超标,实时监控触发告警
任务状态监控
flink任务状态监控使用Grafana创建仪表盘,然后展示Promethus收集到的任务状态和资源使用情况,设置告警规则
如果是金钱,营收统计这种数据出现错误,需要有效的修复和线上容错机制保证数据的稳定性,应该怎么做
数据修复机制:
- 数据通过定期保存的快照恢复。定期保存快照,再重新处理增量数据
- 所有对数据的变更操作日志,重放变更操作日志
容错机制:
- 数据验证:每一步都需要严格的数据验证,比如验证总金额和各项的金额之和是否一致
- 异常数据标记,放到侧输出流,稍后处理或者人工处理
- 数据副本机制,使用分布式数据库,保证数据多副本
- 单点故障的话能快速切换副本
分布式事务:
- 保证多个数据源的操作,要么全部成功,要么全部失败
- 两阶段提交来提交事务
实时监控和报警:
- 监控工具,实时监控数据流中指标,处理延迟和错误
- 异常数据监控,发送邮件通知
- 自动化恢复机制,自动重启故障节点
最简单的监控flink是否正常运行:
假如我们有很多的flink程序在消费kafka,那么我们需要监控这个kafka中有哪些消费者在消费,如果发现消费者少了,说明flink实时任务有问题,需要告警,执行发邮件等操作
ArrayList和LinkedList的区别
ArrayList底层是一个动态数组存储元素,LinkedList底层是一个双向链表存储元素
ArrayList随机访问速度快,时间复杂度是o1,LinkedList随机访问速度慢,时间复杂度是o(n)
ArrayList增加元素的适合如果空间不足会创建一个更大的数组复制旧元素,插入和删除元素需要移动和后续的元素,时间复杂度是on,在末尾添加数据的时间复杂度是o1
LinkedList增加和删除元素的时候不需要移动其他元素,只需要移动指针,时间复杂度是o1,但是在某个特定的位置增加或者删除元素的时候需要先遍历到这个位置,时间复杂度就是on
ArrayList适合频繁读取元素的操作,LinkedList适合频繁增加或者删除元素
创建多线程的几种方式
继承Thread类,重写run方法
1
2
3
4
5
6
7
8
9
10
11
12
13class MyThread extends Thread {
public void run() {
// 线程执行的代码
System.out.println("Thread is running.");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}实现Runnable接口,重写run方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14class MyRunnable implements Runnable {
public void run() {
// 线程执行的代码
System.out.println("Thread is running.");
}
}
public class Main {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}使用 Callable 和 Future
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
class MyCallable implements Callable<String> {
public String call() throws Exception {
// 线程执行的代码
return "Thread result";
}
}
public class Main {
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
MyCallable myCallable = new MyCallable();
Future<String> future = executor.submit(myCallable);
// 获取线程执行结果
String result = future.get();
System.out.println(result);
executor.shutdown();
}
}使用线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
executor.execute(new Runnable() {
public void run() {
// 线程执行的代码
System.out.println("Thread is running.");
}
});
}
executor.shutdown();
}
}
UDF和UDAF和UDTF的区别
UDF是将一列数据转换成另一列数据
1 |
|
UDAF是聚合函数,可以统计一列数据的平均值、最大值等,多行输入返回单个值
1 | import org.apache.hadoop.hive.ql.exec.UDAF; |
UDTF是将一行输入映射多行输出的函数
1 | import org.apache.hadoop.hive.ql.exec.UDF; |
连续两天登录和连续七天登录
1 | create table user_login( |
1 | SELECT |
1 | SELECT |
这个内部的子查询的意思是
DATE(login_time) AS login_date:
使用 DATE 函数将 login_time 转换为仅包含日期部分,忽略时间部分。例如,2024-07-01 10:00:00 会变成 2024-07-01。
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY DATE(login_time)) AS rn:
使用窗口函数 ROW_NUMBER 为每个用户的每个登录日期生成一个连续的行号 rn,按日期排序。例如,某用户的登录日期为 2024-07-01、2024-07-02、2024-07-03,行号会依次为 1、2、3。
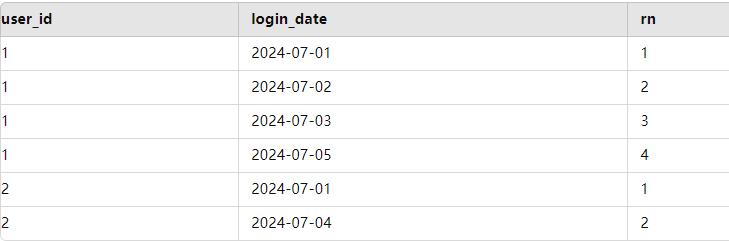
这个外层子查询是
1 | SELECT |
DATEDIFF(A.login_date, A.rn) AS inteval_days:
DATEDIFF 函数计算 login_date 和行号 rn 之间的差异。这里的 DATEDIFF 使用的是日期和行号来生成一个逻辑上的“组标识符”。这个标识符的值在连续日期内是相同的,从而形成一个连续登录的组。
| user_id | login_date | rn | interval_days |
|---|---|---|---|
| 1 | 2024-07-01 | 1 | 2024-06-30 |
| 1 | 2024-07-02 | 2 | 2024-06-30 |
| 1 | 2024-07-03 | 3 | 2024-06-30 |
| 1 | 2024-07-05 | 4 | 2024-07-01 |
| 2 | 2024-07-01 | 1 | 2024-06-30 |
| 2 | 2024-07-04 | 2 | 2024-07-02 |
外层查询是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 SELECT
B.user_id
FROM
(
SELECT
A.user_id,
A.login_date,
DATEDIFF(A.login_date, A.rn) AS inteval_days
FROM
(
SELECT
user_id,
DATE(login_time) AS login_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY DATE(login_time)) AS rn
FROM
user_login
) A
) B
GROUP BY B.user_id, B.inteval_days
HAVING COUNT(1) >= 3;
GROUP BY B.user_id, B.inteval_days:
按用户 ID 和 inteval_days 进行分组。这会将连续登录的天数分到同一个组中。
HAVING COUNT(1) >= 3:
使用 HAVING 子句过滤那些连续登录天数少于三天的组。仅保留连续登录天数大于或等于三天的用户。
最终的结果是返回那些连续登录至少三天的用户 ID。
分组topn最常见方式
假设我们有一个包含销售数据的表 sales,其结构如下
- id:销售记录的唯一标识
- salesperson:销售人员
- product:产品名称
- quantity:销售数量
- sale_date:销售日期
1 | CREATE TABLE sales ( |
找到每个销售人员的前3个销售记录
1 | SELECT |
计算GMV
GMV是一定的时间段内成交的商品的总金额