Doris学习笔记
doris架构
FE
维护元数据
接受,解析查询条件,调度查询执行
BE
leader和follower:元数据高可用,保证数据实时在线恢复
Observer:扩展查询节点,元数据备份,扩展查询能力,Observer不参与写入,只是读取
MysqlClient
提供客户端
Broker
远程读取存储文件,比如读取HDFS或者S3
数据表的创建
基本概念
doris的数据都是关系表形式描述的
建表示例
ROW和COLUMN
ROW:行,一行数据
COLUMN:列,一行数据中的一列
数据模型分为排序列和非排序列
聚合模型分为k和v列,k是维度列,v是指标列
Partition和Tablet
分区:数据按照一定的规则,拆分成多个partition
分桶:分区内还可以进行分桶
数据划分
列定义
Key 列必须在所有Value列之前。
尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串。
对于不同长度的整型类型的选择原则,遵循够用即可。
对于VARCHAR和STRING类型的长度,遵循 够用即可。
所有列的总字节长度(包括 Key和Value)不能超过100KB。
分区分桶
分区
分区可以指定一列或者多列
分区的数量理论上没有上限
当不使用分区的时候,系统会自动生成一个和表名同名的分区,全值范围的分区,该分区对用户不可见,并且不可删改
Range分区
1
VALUES LESS THAN(...)
指定上界,左闭右开,删除分区可能会有空洞
1
2VALUES(...)
指定上下界,生成左闭右开区间
List分区
分桶
只有key列可以分桶,value列不能分桶
Doris采用了列存储模型,其中数据根据key列(维度列)进行组织和存储。key列用于索引和快速查找,而其他列则作为值存储。由于key列是数据存储和检索的基础,对这些列进行分组能够有效利用底层存储结构,从而提高查询效率。
分桶数量理论上没有上限。
使用复合分区
既分区又分桶
假设我们有一个交易表transactions,我们希望按交易日期进行Range分区,同时在每个日期分区内按用户ID进行Hash分区
1 | CREATE DATABASE IF NOT EXISTS example_db; |
适用于有时间维度或者有序值的维度的数据
有历史数据删除的需求
解决数据倾斜问题
多列分区
也就是需要根据多个列进行分区
Range分区
1
2
3
4
5
6PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
)1
2
3
4
5
6
7
8
9
10数据 --> 分区
2017-01-01, 200 --> p201701_1000
**2017-01-01, 2000 --> p201701_1000**
**2017-02-01, 100 --> p201701_1000**
**2017-02-01, 2000 --> p201702_2000**
2017-02-15, 5000 --> p201702_2000
2017-03-01, 2000 --> p201703_all
2017-03-10, 1 --> p201703_all
2017-04-01, 1000 --> 无法导入
2017-05-01, 1000 --> 无法导入这里的分区先看第一个字段,如果第一个字段就可以判断分区了,就不管第二个字段了,直接入分区
List分区
顺序比较
1
2
3p1_city: [("1", "Beijing"), ("1", "Shanghai")]
p2_city: [("2", "Beijing"), ("2", "Shanghai")]
p3_city: [("3", "Beijing"), ("3", "Shanghai")]1
2
3
4
5
61, Beijing ---> p1_city
1, Shanghai ---> p1_city
2, Shanghai ---> p2_city
3, Beijing ---> p3_city
1, Tianjin ---> 无法导入
4, Beijing ---> 无法导入
Properties
副本数量
replication_num
最大副本数量取决于独立ip数量,而不是BE数量,因为一台机器上可以有多个BE,所以副本需要在多台机器上,而不是一台机器的多个BE上。在同一台物理机器上运行多个BE实例,可以实现资源隔离。每个实例分配一定的CPU、内存和磁盘资源,避免单个实例过度消耗资源,影响系统的整体性能。提高容错能力和负载均衡
存储介质
默认存储介质在fe.conf中指定default_storage_medium=xxx
迁移时间
storage_cooldown_time
如果没有指定storage_cooldown_time,则默认30天后,数据会从SSD自动迁移到HDD 上。如果指定了storage_cooldown_time,则在到达storage_cooldown_time时间后,数据才会迁移。
数据模型
Aggregate
将列分为key和value
没有设置AggregationType的为key
设置了Aggregation的是Value我们导入数据的时候所有key相同的列会聚合为一行,Value会按照设置的Aggregate进行聚合
Aggregation四种聚合:
(1) SUM
(2) REPLACE:下一批数据中的Value会替代上一次的value
(3) REPLACE_IF_NOT_NULL:
遇到null不更新
(4) MAX(5) MIN
Uniq
某些情况用户关注key的唯一性,相当于Replace,就是替换
Duplicate
不进行聚合,指定的key只是要按照这些key进行排序
这种排序会让我们可以根据排序的字段快速定位到数据
主要是因为使用了有序存储和二分查找
假设我们有一张表是如下数据内容:
| user_id | action_type | action_time | action_value |
|---|---|---|---|
| 1 | view | 2024-01-01 09:00:00 | 5 |
| 1 | click | 2024-01-01 10:00:00 | 10 |
| 2 | click | 2024-01-02 11:00:00 | 20 |
| 3 | view | 2024-01-03 12:00:00 | 15 |
| 3 | click | 2024-01-04 13:00:00 | 25 |
SELECT * FROM user_actions WHERE user_id = 1;
- 利用二分查找快速定位到user_id = 1的开始位置。
- 顺序读取符合条件的记录:
- 1 | view | 2024-01-01 09:00:00 | 5
- 1 | click | 2024-01-01 10:00:00 | 10
数据聚合的阶段
数据写入阶段
当数据写入Doris时,聚合操作可以在数据写入过程中发生。Doris支持Aggregate Key模型,这种模型在数据写入时就会进行聚合。例如,对于相同的key,新的数据会与已有的数据进行聚合操作(如求和、计数等)。
查询执行阶段
查询执行过程中的聚合通常分为两阶段:
本地聚合:每个BE节点会在本地对分配到的数据进行聚合,比如SUM就会每个BE把自己的数据先进行求和,然后发给FE
全局聚合:FE再进行一次整体的聚合求和。得到最终的SUM
数据导入阶段
在数据导入阶段(例如使用ETL工具进行批量数据加载时),Doris也会进行聚合操作。导入数据时,可以指定聚合策略,使得数据在导入时就进行必要的聚合处理,以减少查询时的计算量。
数据模型的选择
Aggregate模型会降低扫描的数据量和查询数据量,但是对count非常不好,
解决方法是加一列,值都为1,SUM这个列来模拟COUNT操作
Uniq模型没有查询优势,没有SUM聚合方式
Duplicate和普通查询一样,但是指定key,按照key来查询会更快
动态分区
表级别的分区实现生命周期管理
建表的时候指定
1 | PROPERTIES |
运行的时候修改
1 | ALTER TABLE tbl1 SET |
动态分区参数
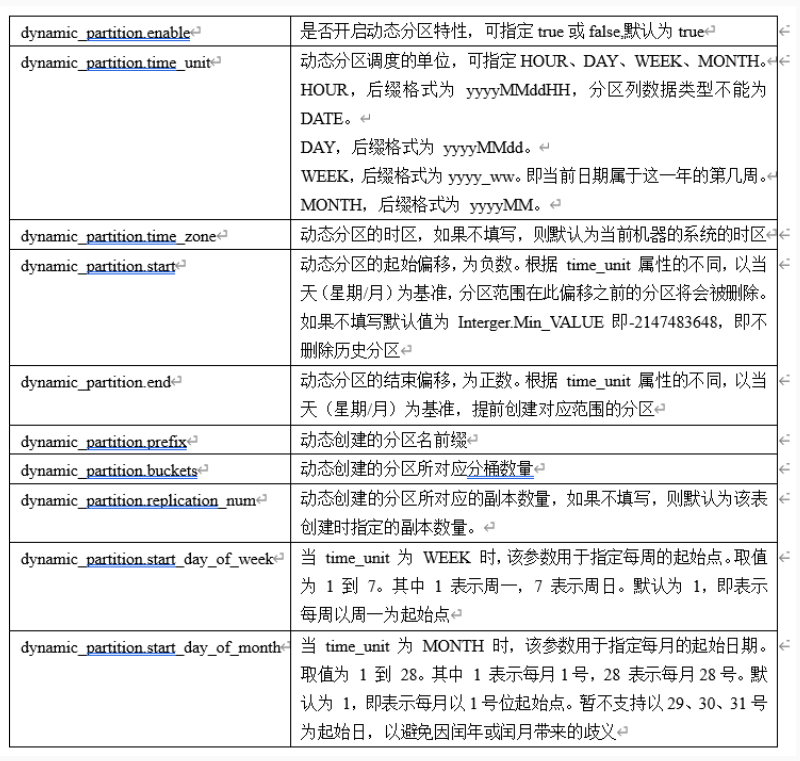
- dynamic_partition.enable
- dynamic_partition.time_unit
- dynamic_partition.start
- dynamic_partition.end
这四个配置最主要
热分区
假设今天是 2024-06-26,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置 storage_medium 和 storage_cooldown_time 参数
这里设置历史分区时间是往前3天,再往后三天,热分区是2,就是今天和明天这两天是热分区,放在SSD里面
1 | p20210517:["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59 |
历史分区
这里必须设置reserved_history_periods
我们举例说明。假设今天是 2021-09-06,按天分类,动态分区的属性设置为:
1 | time_unit="DAY/WEEK/MONTH", \ |
那么这些设置时间的数据,即使没有在动态分区里面,也会进行保存历史分区
[“2020-06-01”,”2020-06-20”],
[“2020-10-31”,”2020-11-15”]
RollUp
上卷,试按照某种粒度进一步进行聚合
在用户创建的表上,再创建一个更粗粒度的表,在物理上单独存储
示例
创建一个表的rollup表
1 | alter table example_site_visit2 add rollup rollup_cost_userid(user_id,cost); |
查看执行计划
1 | explain SELECT user_id, sum(cost) FROM example_site_visit2 GROUP BY user_id; |
查看所有的roolup表
1 | SHOW ALTER TABLE ROLLUP; |
前缀索引
因为doris的数据结构是SSTable的数据结构,这种数据节后,是按照指定的列进行排序存储的,所以按照列的顺序进行查询会加快查询的速度。比如列的第一个是user_id,第二个是age,那么查询where user_id = 18290 and age = 20就会比where age = 20要更加的快
表在创建的时候可能没有考虑到列的顺序,那么我们就创建对应顺序的rollup表,这样查询的时候就是查询的rollup表了,就会加大查询速度
物化视图
也就是对聚合后的结果的一个预先存储
可以对那些重复使用相同子查询结果的性能大幅提升
物化视图和rollup的区别
物化视图是Rollup的超集,rollup有限制
物化视图的创建规则
当多个查询都可以匹配到这张物化视图的时候再进行创建,因为创建物化视图和维护它也需要资源
不需要给所有的维度都创建物化视图
使用
1 | CREATE MATERIALIZED VIEW seller_amt AS |
用户查询的时候就会自动匹配到这个物化视图
1 | SELECT seller_id,sum(sale_amt) |
如果创建了多个物化视图会自动选择最优的物化视图
限制
物化视图不支持表达式比如sum(a+b),只支持单列
删除数据的时候需要先删除物化视图
单表上物化视图过多会影响导入效率
相同列不同聚合函数不能在一张物化视图中select sum(a),min(a) from table不可以
示例
1 | create materialized view advertiser_uv as |
这里的bitmap_union(to_bitmap(user_id))与count(distinct)一致,这种写法可以直接得出uv的结果。因为这里的user_id是int类型,所以这里将这个int类型需要先转换成bitmap类型再使用,也就是使用to_bitmap
这里我们使用
SELECT advertiser, channel, count(distinct user_id)
FROM advertiser_view_record
GROUP BY advertiser, channel;
的时候就会自动匹配到上面创建的物化视图
修改表
rename
1)将名为 table1 的表修改为 table2
ALTER TABLE table1 RENAME table2;
2)将表 example_table 中名为 rollup1 的 rollup index 修改为 rollup2
ALTER TABLE example_table RENAME ROLLUP rollup1 rollup2;
3)将表 example_table 中名为 p1 的 partition 修改为 p2
ALTER TABLE example_table RENAME PARTITION p1 p2;
partition
emmm,这个太多了,现用现查吧
rollup
基于一个rollup,来创建另一个rollup
前缀索引的顺序不同,面对不同的查询顺序的情况
创建 index: example_rollup_index2,基于 example_rollup_index(k1,k3,v1,v2)这里的k1,k3,v1,v2 指的是这个索引中的列字段
1 | ALTER TABLE example_db.my_table |
自定义rollup超时时间
创建index,自定义rollup超时时间为一小时
1 | ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index(k1,k3,v1) PROPERTIES("timeout" = "3600"); |
删除rollup
1 | ALTER TABLE example_db.my_table |
表结构变更
- 增加列
- 删除列
- 修改列类型
- 改变列顺序
删除数据
1 | delete from student_kafka where id=1; |
注意:
- 这个语句只能针对Partition级别进行删除
- 如果一个表有多个Partition含有需要删除的数据,需要多次针对不同的Partition的delete语句
- where后面的条件只能针对key列
- 在执行了删除delete命令后不会立即释放磁盘空间,真正的删除是BE中进行数据Compaction
1 | DROP PARTITION |
删除分区,这个删除分区的方式是比较推荐的,不会影响到查询的速率,真正后台删除数据需要延迟10分钟左右
数据的导入和导出
数据导入
概念
将用户原始数据导入到doris中,用户可以通过Mysql客户端来查询数据,Doris提供不同的使用方式(异步,同步)
分类
Broker load
概念
通过 Broker 进程访问并读取外部数据源(如 HDFS)导入到 Doris。用户通过 Mysql 协议提交导入作业后,异步执行。通过 SHOW LOAD 命令查看导入结果。
原理
FE生成plan,根据BE个数将这个plan分给BE执行,BE执行的时候会从Broker拉取数据,对数据Transform后将数据导入系统,FE决定导入是否成功
适用场景
Broker可以访问的存储系统,类似HDFS,数据量在几十到百GB
Stream Load
概念
用户通过http协议带着原始数据创建导入。主要用于快速导入本地文件或者数据流中的文件
适用场景
导入本地文件,支持csv和json
用户无法手动取消
原理
不通过fe,doris会选择一个be作为Coordinator节点,这个节点负责接收数据并且分发数据到其他的数据节点,用户通过http提交导入命令,导入最后结果,通过这个Coordinator BE返回给用户
Insert
直接导入数据,从一张表到另一张表
Multi Load
概念
Multi Load是高级版本的Stream Load,用户可以通过http协议提交多个导入作业
Routine Load
概念
这种导入类似于一个Flink这种数据流的导入,用户通过Mysql协议提交导入作业,生成一个常驻的线程,不间断的从数据源(如 kafka)中读取数据并且导入到Doris上
适用场景
目前仅支持无认证的kafka访问和通过SSL方式认证的kafka集群,支持的消息格式是csv和json格式
原理
- FE会通过JobScheduler将一个导入作业拆成若干个Task,每个Task负责的BE会导入指定的一部分数据
- 在BE上一个Task当做一个普通导入的任务,然后通过Stream Load的导入机制进行导入,导入完成后会向FE进行汇报
- FE中的JobScheduler根据汇报的结果,继续生成后续新的Task,或者对失败的Task进行重试
- 整个导入的作业不断产生新的Task来对数据进行不间断的导入
Binlog Load
概念
CDC增量同步数据库
使用
需要开启mysql 的binlog。然后需要配置一个Canal端
这个Canal端的主要用途是基于mysql数据库增量日志解析,提供增量数据的订阅和消费
S3导入
概念
用户通过S3协议直接导入数据,用法和Broker Load 类似。
Broker load是一个异步的导入方式,支持的数据源取决于Broker进程支持的数据源。
用户需要通过MySQL协议创建Broker load导入,并通过查看导入命令检查导入结果。
数据导入总结
- Broker load是从外部数据源普通导入
- Stream Load 适用于对本地文件的快速导入
- Insert 是从一张表导入到另一张表中
- Multi Load 是可以直接提交多个导入的作业
- Routine Load是数据流导入,从kafka可以一直导入到Doris中
- Binlog Load是CDC的导入,需要开启binlog
- S3 从S3直接进行导入和Broker Load一样,不过是基于S3的导入
数据导出
export
export导出是将数据导出到HDFS/BOS上,这里的BOS是一种云端存储
原理
用户提交Export作业到FE
FE调度两阶段执行export任务
- FE生成TASK,向BE发送快照命令,对所有涉及到Table做一个快照,生成多个查询任务
- FE生成TASK,开始执行查询计划
查询计划拆分:一个导出任务会生成多个查询计划,每个计划扫描一部分的tablet,每个查询计划扫描的Tablet个数默认是5,这个可以更改
查询计划执行:
一个作业的查询计划顺序执行每个查询计划将数据每1024行变成一个batch调用Broker写入到存储中
重试三次,超过三次整个任务失败
doris会先在存储路径建立一个临时目录,数据先写入临时目录,数据导出后,将整个文件rename到用户指定路径
使用
1 | EXPORT TABLE db1.tbl1 |
- label:本次导出作业的标识。后续可以使用这个标识查看作业状态。
- column_separator:列分隔符。默认为 \t。支持不可见字符,比如 ‘\x07’。
- columns:要导出的列,使用英文状态逗号隔开,如果不填这个参数默认是导出表的所有列。
- line_delimiter:行分隔符。默认为 \n。支持不可见字符,比如 ‘\x07’。
- exec_mem_limit: 表示 Export 作业中,一个查询计划在单个 BE 上的内存使用限制。默认 2GB。单位字节。
- timeout:作业超时时间。默认 2小时。单位秒。
- tablet_num_per_task:每个查询计划分配的最大分片数。默认为 5。
查询结果导出
1 | SELECT * FROM example_site_visit |
properties
配置包括
- column_separator:列分隔符,仅对 CSV 格式适用。默认为 \t。
- line_delimiter:行分隔符,仅对 CSV 格式适用。默认为 \n。
- max_file_size:单个文件的最大大小。默认为 1GB。取值范围在 5MB 到 2GB 之间。超过这个大小的文件将会被切分。
- schema:PARQUET 文件schema信息。仅对 PARQUET 格式适用。导出文件格式为PARQUET时,必须指定schema。
查询
查询设置
限制
单BE节点上默认使用的查询内存不能超过2GB,可以更改这个配置
SET GLOBAL exec_mem_limit = 8589934592;超时时间
默认300s超时时间,可以改为60s
set global query_timeout = 60;查询重试
当一个查询挂掉了,就自动在其他的连接上重试
join查询
Broadcast Join
默认实现的join方式及,小表体检过滤后会将这个小标的内容广播到大表所在的各个节点,形成一个内存表,然后读出这个大表的数据再hash join
shuffle join
小表过大就会变成这种join
Colocation Join
限制
建表的时候两张表的分桶列类型和数量需要完全一致,桶数也要一致
所有表的所有分区的分区副本数需要一致
Bucket shuffle join
设置Session变量后,优先选择Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join,会更节省内存开销
Runtime Filter
在join查询运行的时候生成过滤条件,减少扫描的数据量
使用
指定Filter
1
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
建表
1
2
3
4
5
6
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test2 VALUES (3), (4), (5);
这里使用的时候需要仔细看一下
SQL函数
这里的函数很多,就不一一列出,主要说两个可以查询函数和查看函数具体信息的函数
查看函数名
1
show builtin functions in test_db;
这个命令可以查看在test_db库内可以使用的所有sql函数
查看函数具体信息
1
show full builtin functions in test_db like 'year';
集成其他系统
集成flink
doris的Source
1 |
|
doris的Sink
这种是json的格式写入,下文有对rowdata的方式写入
1 | public static void main(String[] args) throws Exception { |
doris的rowDataSink
这种方式和json方式不一样,会避免一些类型转换的错误,使用rowdata的方式写入,推荐这种写法
1 | public static void main(String[] args) throws Exception { |
Doris的sql
1 | public static void main(String[] args) { |
ODBC外部表
这个功能比较重要,相当于一个外部表的使用
支持多种数据源接入Doris
支持doris和各种数据源中的表进行联合查询,进行更加复杂的分析
通过insert into的方式将doris查询的结果写入到外部表
这个使用的时候需要好好看一下
最主要的是doris on mysql和doris on es
外部表的主要作用是将两张表连起来,比如使用了doris ON Mysql就会当mysql增加数据或者减少数据,doris也会增加数据或者减少数。反之,doris增加数据或者减少数据,mysql也会增加数据或者减少数据
优化
优化暂不考虑,使用的时候再看
数据备份
监控
这里使用prometheus进行监控,使用grafana进行展示
数据备份
快照上传
快照是对当前数据文件的产生的一个硬链,快照完成后会对快照文件进行逐一上传
元数据的准备和上传
数据快照上传完成后,会将对应的元数据写成本地文件再通过Broker上传到远程仓库
使用
创建一个远程仓库路径
1 | CREATE REPOSITORY `hdfs_ods_dw_backup` |
执行备份
1 | BACKUP SNAPSHOT [db_name].{snapshot_name} |
1 | BACKUP SNAPSHOT test_db.backup1 |
恢复数据
建立元数据
本地创建一个空快照
下载快照
生效快照
使用
1
2
3
4
5
6
7
8RESTORE SNAPSHOT [db_name].{snapshot_name}
FROM `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)] [AS `tbl_alias`],
...
)
PROPERTIES ("key"="value", ...);1
2
3
4
5
6
7
8RESTORE SNAPSHOT example_db1.`snapshot_1`
FROM `example_repo`
ON ( `backup_tbl` )
PROPERTIES
(
"backup_timestamp"="2021-05-04-16-45-08",
"replication_num" = "1"
);
新特性
向量化执行引擎
概念
向量化执行引擎会极大突破sql执行引擎的性能限制
使用
set enable_vectorized_engine = true;set batch_size = 4096;
注意事项
注意的是Null值会导致执行引擎性能劣化,所以最好是在使用向量化引擎之前先把所有的Null值改成其他的特性值
支持hive外表
概念
提供了Doris直接访问Hive外表的能力
使用
1 | CREATE [EXTERNAL] TABLE table_name ( |
支持使用mysqlDump工具导出数据或者表结构
使用
导出数据
1
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test_db --tables user > dump1.sql
导入数据
source /opt/module/doris-1.0.0/dump1.sql