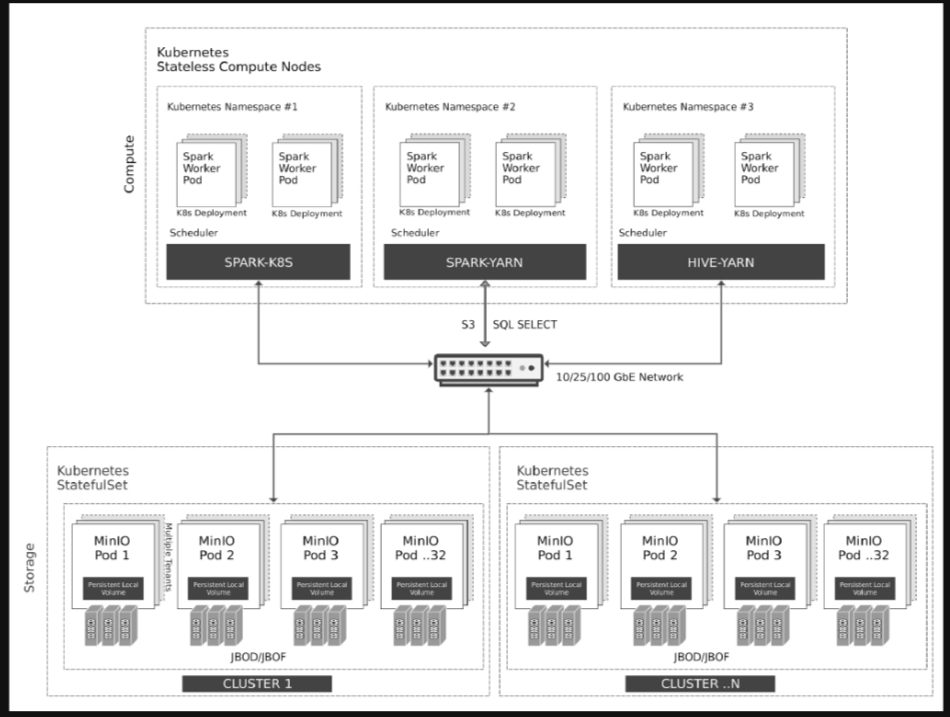
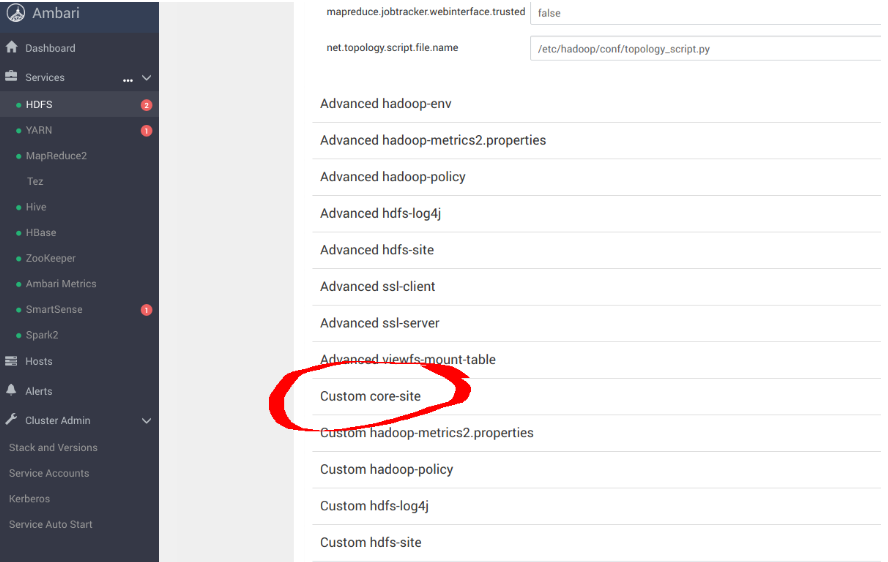
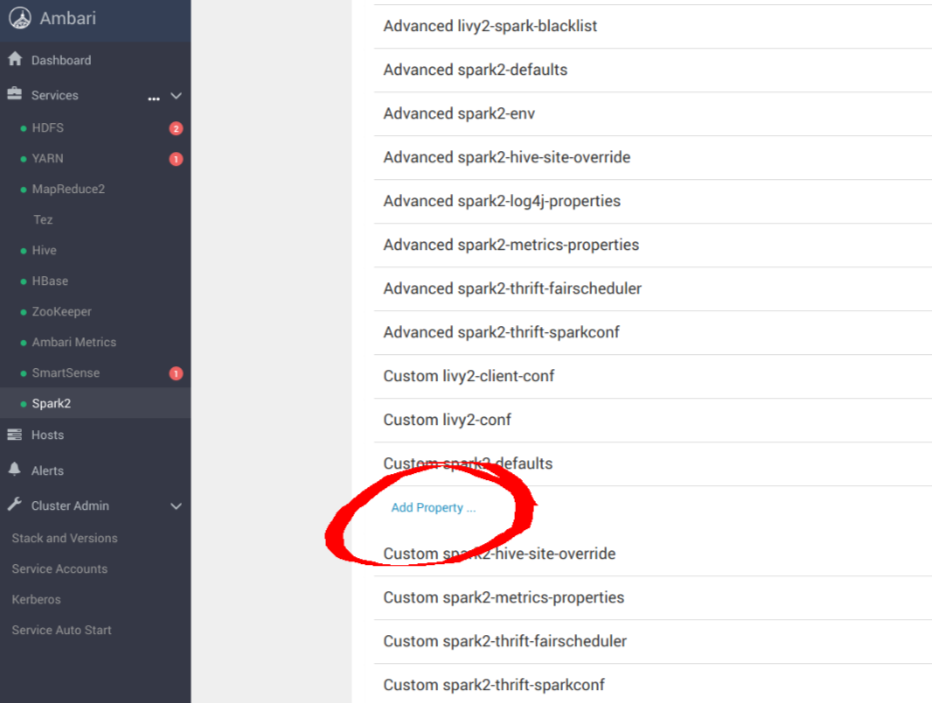
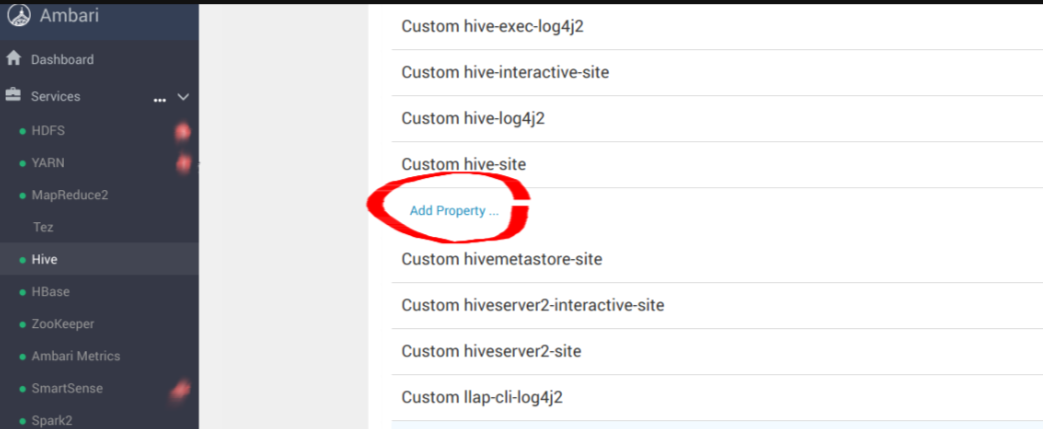
mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs mapred.maxthreads.partition.closer=0 # Asynchronous map flushers mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM mapreduce.reduce.speculative=false # Disable speculation for reducing mapreduce.task.io.sort.factor=999 # Threshold before writing to drive mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive
spark.hadoop.fs.s3a.access.key minio spark.hadoop.fs.s3a.secret.key minio123 spark.hadoop.fs.s3a.path.style.access true spark.hadoop.fs.s3a.block.size 512M spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a spark.hadoop.fs.s3a.committer.magic.enabled false spark.hadoop.fs.s3a.committer.name directory spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true spark.hadoop.fs.s3a.committer.staging.conflict-mode append spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging spark.hadoop.fs.s3a.committer.staging.unique-filenames true spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO spark.hadoop.fs.s3a.connection.establish.timeout 5000 spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns spark.hadoop.fs.s3a.connection.ssl.enabled false spark.hadoop.fs.s3a.connection.timeout 200000 spark.hadoop.fs.s3a.endpoint http://minio:9000 spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A