Flink调优
目录
启动命令
1 | bin/flink run \ |
内存模型

- JVM内存:包括JVM元空间内存和JVM执行开销内存。JVM元空间默认:256MB,JVM执行开销:JVM执行自身需要的内容,包括堆栈和IO,默认0.1
- 框架内存:TaskManager本身:堆外和堆内都默认是128MB
- Task内存:Task执行用户代码需要的内存,默认0
- 网络内存:网络数据交换使用的对外内存,默认0.1
- 管理内存:RocksDB的本地内存和缓存中间结果,哈希表,排序内存,默认0.4
内存计算

指定为4G,每一块内存得到大小如下:
(1)计算Flink内存
JVM元空间256m
JVM执行开销: 4g*0.1=409.6m,在[192m,1g]之间,最终结果409.6m
Flink内存=4g-256m-409.6m=3430.4m
(2)网络内存=3430.4m*0.1=343.04m,在[64m,1g]之间,最终结果343.04m
(3)托管内存=3430.4m*0.4=1372.16m
(4)框架内存,堆内和堆外都是128m
(5)Task堆内内存=3430.4m-128m-128m-343.04m-1372.16m=1459.2m
QPS/TPS
一般使用这两个来描述数据情况
QPS
表示每秒能处理的查询次数
如果一个搜索引擎在10秒内处理了500个搜索请求,则其QPS为50(500 / 10)。
TPS
TPS表示系统每秒能够处理的事务次数。
如果一个电商平台在一分钟内处理了3000个订单事务,则其TPS为50(3000 / 60)。
CPU资源
将DefaultResourceCalculator分配策略改成DominantResourceCalculator
在yarn-site.xml中更改如下配置
1 | <property> |
DefaultResourceCalculator:只考虑CPU核数进行资源分配
DominantResourceCalculator:考虑多种资源基于z最主要的资源进行决策
并行度设置
开发完成后进行压测,并行度给到10以下,测试单个并行度的处理上限,总QPS/单并行度的处理能力 = 并行度。最后的并行度在*1.2,富余一些资源
Source端并行度测试
kafka作为source的时候,并行度最好是等于kafka的分区数,但是不要大于kafka的分区数要不就会导致并行度空闲,资源浪费
Transform端并行度测试
keyby之前的算子并行度可以和source一致,keyby之后的算子建议设置并行度是2的整数倍
Sink并行度
要参考下游的服务能不能撑住高并发的写入,来计算sink的并行度
状态和CheckPoint调优
RocksDB
和hbase很像,先把状态写入到内存再落盘,查数据先去内存查,内存没有再去磁盘查
开启State访问性能监测
-Dstate.backend.latency-track.keyed-state-enabled=true \
开启增量检查点和本地恢复
增量检查点
设置检查点增量存储在状态后端,节省资源
state.backend.incremental: true #默认false,改为true。
或代码中指定new EmbeddedRocksDBStateBackend(true)
开启本地恢复
state.backend.local-recovery: true
设置多目录
1 | # flink-conf.yaml |
注意:这里的目录必须是多磁盘的目录,而不是单磁盘的目录
设置预定义选项
1 | bin/flink run \ |
flink针对不同的设置为RocksDB提供了预定义的选项集合,目前是DEFAULT。总共包括:DEFAULT、SPINNING_DISK_OPTIMIZED、SPINNING_DISK_OPTIMIZED_HIGH_MEM或FLASH_SSD_OPTIMIZED。
一般可以更改为state.backend.rocksdb.predefined-options: SPINNING_DISK_OPTIMIZED_HIGH_MEM
#设置为机械硬盘+内存模式
有条件上SSD的直接指定为FLASH_SSD_OPTIMIZED
CheckPoint设置
一般设置Checkpoint时间间隔是1~5分钟
状态很大的任务会设置5~10分钟
反压处理
定位反压节点
禁用算子链
1
2
3
4
5// 第一个算子(map操作)
SingleOutputStreamOperator<String> mapOperator = source
.map(value -> "map: " + value)
.name("MapOperator")
.disableChaining(); // 禁用算子链利用flink ui进行定位
分析瓶颈算子

有时候在一条输入多条输出的时候可能会出现这种情况
使用Metrics定位

反压的原因和处理
查看数据是否倾斜
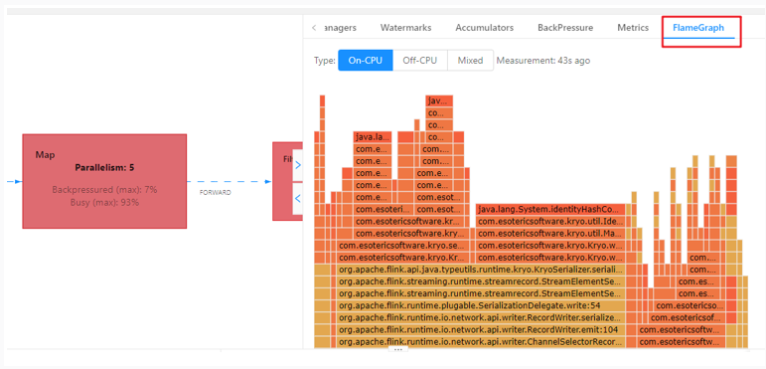
火焰图分析
火焰图的从下到上就是执行的函数横向是函数的执行时长
颜色没有特别的意义
看一下顶层的函数的占据宽度最大,如果有平顶的情况,这个函数就是有问题
外部组件交互
如果是发现Source或者Sink性能差,就要对第三方组件进行处理

常见的处理是
- 异步io+热缓存优化读写性能
- 先攒批再读写
数据倾斜
keyby之后的聚合操作存在数据倾斜
使用LocalKeyBy
处理策略
- 局部聚合:在本地(Task Manager内部)先进行一次聚合,减少发送到下游的数据量。
- 随机前缀:在键前加上一个随机前缀,使得相同键的数据分散到不同的子任务中,之后再去除前缀进行全局聚合。
1 | public class LocalKeyByFlatMapFunc extends KeyedProcessFunction<String, Tuple2<String, Long>, Tuple2<String, Long>> implements CheckpointedFunction { |
示例分析
listState:用于存储Flink状态,确保在Checkpoint时可以恢复。
localBuffer:本地缓存,用于存放聚合的数据。
batchSize:缓存的数据量大小,达到这个大小后,数据将被发送到下游。
currentSize:计数器,用于跟踪当前接收到的数据量。
数据处理逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
public void processElement(Tuple2<String, Long> value, Context ctx, Collector<Tuple2<String, Long>> out) throws Exception {
Long count = localBuffer.getOrDefault(value.f0, 0L);
localBuffer.put(value.f0, count + value.f1);
if (currentSize.incrementAndGet() >= batchSize) {
for (Map.Entry<String, Long> entry : localBuffer.entrySet()) {
out.collect(Tuple2.of(entry.getKey(), entry.getValue()));
}
localBuffer.clear();
currentSize.set(0);
}
}将新数据添加到localBuffer中,并进行本地聚合。
当接收到的数据量达到batchSize时,将缓存的数据发送到下游,并清空缓存。
状态管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public void snapshotState(FunctionSnapshotContext context) throws Exception {
listState.clear();
for (Map.Entry<String, Long> entry : localBuffer.entrySet()) {
listState.add(Tuple2.of(entry.getKey(), entry.getValue()));
}
}
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Long>> descriptor = new ListStateDescriptor<>(
"buffered-state",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
);
listState = context.getOperatorStateStore().getListState(descriptor);
localBuffer = new HashMap<>();
if (context.isRestored()) {
for (Tuple2<String, Long> element : listState.get()) {
localBuffer.put(element.f0, element.f1);
}
}
}snapshotState:在Checkpoint时保存当前状态。
initializeState:在任务初始化时恢复之前的状态。
主程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Long>> source = env.fromElements(
Tuple2.of("key1", 1L),
Tuple2.of("key2", 1L),
Tuple2.of("key1", 1L),
Tuple2.of("key3", 1L)
);
DataStream<Tuple2<String, Long>> withRandomPrefix = source.map(value -> {
String randomPrefix = String.valueOf(new Random().nextInt(10));
return Tuple2.of(randomPrefix + "-" + value.f0, value.f1);
});
DataStream<Tuple2<String, Long>> localAggregated = withRandomPrefix
.keyBy(value -> value.f0)
.process(new LocalKeyByFlatMapFunc(100));
DataStream<Tuple2<String, Long>> globallyAggregated = localAggregated.map(value -> {
String originalKey = value.f0.split("-", 2)[1];
return Tuple2.of(originalKey, value.f1);
}).keyBy(value -> value.f0)
.sum(1);
globallyAggregated.print();
try {
env.execute("Handle Data Skew");
} catch (Exception e) {
e.printStackTrace();
}
}数据源:模拟一些输入数据。
随机前缀:给每个键加上一个随机前缀,以避免数据倾斜。
局部聚合:使用LocalKeyByFlatMapFunc进行本地聚合。
去除前缀并全局聚合:去除随机前缀后,再次根据原始键进行全局聚合,得到最终结果。
执行作业:启动Flink作业。
keyby之前的聚合存在数据倾斜
直接使用rescale
keyby之后的窗口聚合操作存在数据倾斜
两阶段聚合
1 | public class TwoPhaseAggregationExample { |
第一阶段聚合:
- 拼接随机前缀:为每个键添加一个随机前缀,使数据分布更均匀。
- 窗口聚合:按照带有随机前缀的键进行窗口聚合,使用10秒的滚动窗口。
- 输出结果:输出的结果包括键、聚合值和窗口结束时间。
第二阶段聚合:
- 去掉随机前缀:恢复原始键,以便进行第二阶段聚合。
- 二次分组:按照原始键和窗口结束时间进行分组。
- 聚合:对第一次聚合的结果进行最终聚合,得到每个页面在每个窗口的访问次数。
第一阶段使用随机前缀分散数据负载,第二阶段恢复原始键并进行最终聚合
Job优化
DataGen造数据
- RandomGenerator
1
2
3
4
5
6
7
8
9
10new RandomGenerator<OrderInfo>() {
public OrderInfo next() {
return new OrderInfo(
random.nextInt(1, 100000),
random.nextLong(1, 1000000),
random.nextUniform(1, 1000),
System.currentTimeMillis());
}
} - SequenceGenerator
这个可以造出顺序的数据1
2
3
4
5
6
7
8
9
10
11
12new SequenceGenerator<UserInfo>(1, 1000000) {
RandomDataGenerator random = new RandomDataGenerator();
public UserInfo next() {
return new UserInfo(
valuesToEmit.peek().intValue(),
valuesToEmit.poll().longValue(),
random.nextInt(1, 100),
random.nextInt(0, 1));
}
}
算子指定UUID
建议算子指定UUID,这样在日志中可以更方便的定位到对应的算子
.map(data -> JSONObject.parseObject(data)).uid("parsejson-map").name("parsejson-map");
在每个算子后面加上.uid(算子名字).name(和前面算子名字相同)
常见故障排除
非法故障异常
IllegalConfigurationException
配置冲突,或者有无效的配置值
Java堆空间异常
OutOfMemoryError: Java heap space
内存不够
直接缓冲存储器异常
OutOfMemoryError: Direct buffer memory
内存限制太小
元空间异常
OutOfMemoryError: Metaspace
加大 JVM 元空间 TaskManagers 或JobManagers
网络缓冲区数量不够
增加网络内存
超出容器内存异常
checkpoint失败
kafka动态发现分区
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, 30 * 1000 + "");
当被订阅的topic创建了新的partition,flink可以动态发现新创建的partition进行消费
独享插槽slot
slot是一个资源管理机制,用于控制作业之间不同任务之间分配slot,默认是来自一个job的不同task的小任务都是一个共享组(default)的,但是这个可能会导致有些任务被其他任务影响
如果希望小任务独享一个slot,为了性能隔离,保证这个任务对性能要求很高很重要,要避免被打扰
可以加上.slotSharingGroup("独享组");但是建议一般情况不使用
Flink并行度和资源设置
Flink并行度设置
source,transform,sink的并行度都要和kafka分区保持一致
计算大任务时候,source和sink可以保持一致,transform可以设置2的n次方
Flink资源设置
测试资源是否足够:
资源设置后,然后压测,看看每个并行度的处理上限
eg:当每个并行度处理5000条/s开始出现反压,我们设置三个并行度,程序的处理上限就是15000条/s
flink快慢流关联
在flink中我们一般可以使用interval join(间隔关联)来实现快慢流关联,也可以使用自定义定时器实现
但是这种方案我们一般使用各自落表,微批调度的方案。快慢流的概念其实就是两个事件的间隔时间过长,这是业务决定的,比如支付和售后的关联,最好的方式就是推到olap后微批次调度
flink做中间层缓批处理
flink先做rollup统计,然后窗口适配流量缓批写入到doris,在doris里面按照时间粒度rollup,这样就是flink做中间层做缓冲处理
flink HA 机制
YARN集群高可用
只需要一个jobManager,当这个jobManager发生失败的时候,yarn会重新启动
更改yarn-site.xml中配置yarn.resourcemanager.am.max-attempts,这个标识yarn的appliaction master重启的最大次数
还需要配置flink-conf.xml中的最大重试次数yarn.application-attempts:10
这个配置表示程序启动失败的话yarn会重试9次(9次重试+1次启动),如果启动了10次还是失败,yarn才会把这个任务定义为失败
flink分布式缓存
分布式缓存最广泛的一个应用就是表和表join的时候,如果一个表很大,另一个表很小,就把这个很小的表缓存下来,在每个taskManager都缓存一份然后去join操作
1 | /** |
故障恢复和重启策略
故障恢复
jobmanager.execution.failover-strategy: region
这个配置在flink-conf.xml中。有两个配置项可以配置一个是full一个是默认的region
full是task出现故障是重启所有的task,实际生产环境一个大作业可能有好多task不能出现一次异常就全部重启
region是集群只重启有问题的那一部分,这就是检查点的局部重启策略,flink会把任务分为多个region,当某一个task发生了故障,flink会计算需要故障恢复的最小的region
region重启策略
- 故障的task所在的region需要重启
- region上游如果依赖的数据出现丢失也要重启
- region下游的数据都要重启
flink重启策略
- 无重启策略:如果没有设置检查点程序就不会重启
- 固定延迟重启:如果设置了检查点,但是没有设置重启策略,那么就是固定延迟重启
- 失败率重启
固定延迟重启:
1 | final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); |
也就是固定失败后多长时间重启一次
失败率重启:
举个例子也就是我们要五分钟内失败次数大于3次的算作正式重启失败,每五秒尝试重启一次
1 | env.setRestartStrategy(RestartStrategies.failureRateRestart( |
集群并行度数量计算
假设我们每个taskManager有3个slot,那么我们就说集群有3*taskManager数量个slot,就可以说集群可以执行多少并发数量