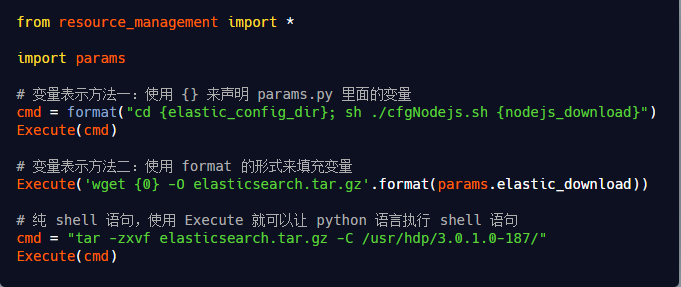
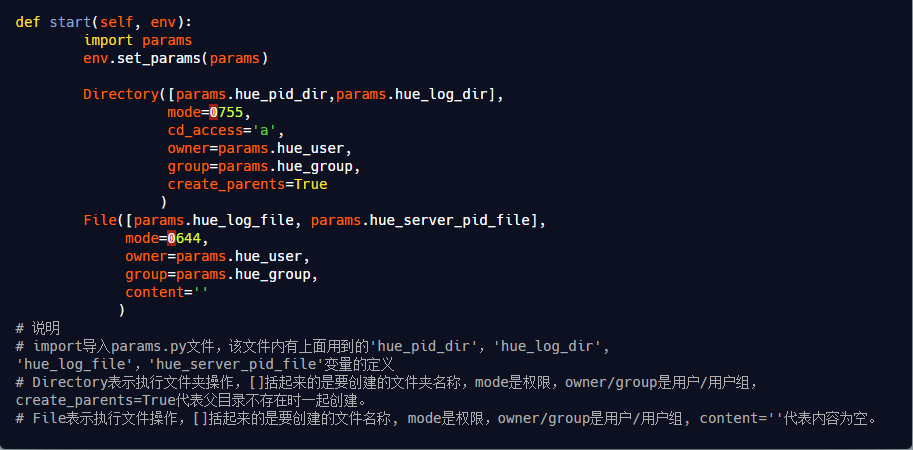
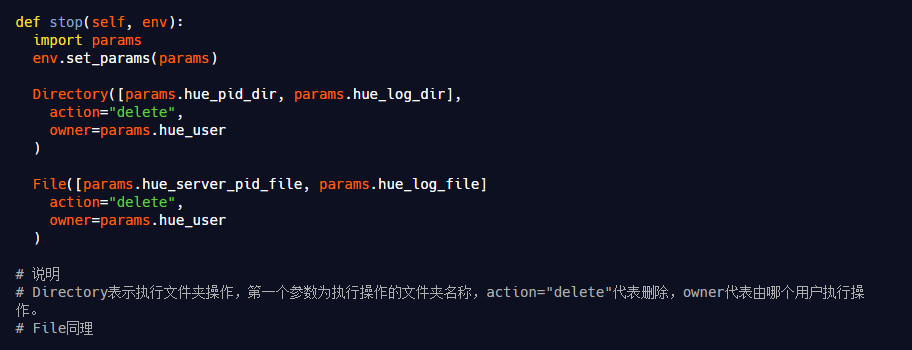
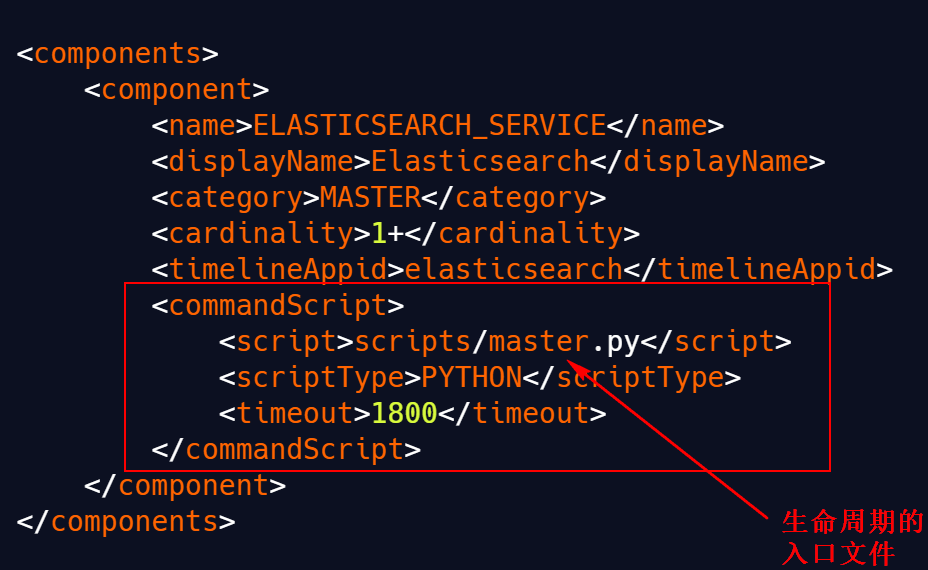
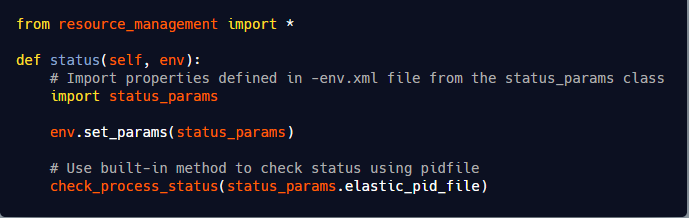
<!-- Paths --> <property> <name>path_data</name> <display-name>Path data</display-name> <value>/elasticsearch/data</value> <description>Path to directory where to store the data (separate multiple directory by comma)</description> <final>true</final> <value-attributes> <type>directories</type> <!--<overridable>false</overridable>--> </value-attributes> <on-ambari-upgradeadd="true"/> </property>
<!-- Network --> <!--<property>--> <!--<name>network_host</name>--> <!--<value>{{hostname}}</value>--> <!--<description>Set the bind address to a specific IP (IPv4 or IPv6)</description>--> <!--</property>-->
<property> <name>elasticsearch_head_port</name> <display-name>Elasticsearch head port</display-name> <value>9100</value> <description>Elasticsearch head port</description> </property>
<property> <name>content</name> <display-name>Elasticsearch config file template</display-name> <description>This is the template for elasticsearch.yml file</description> <value> # ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please see the documentation for further information on configuration options:
# ---------------------------------- Cluster ----------------------------------- # Use a descriptive name for your cluster: cluster.name: {{cluster_name}}
# ------------------------------------ Node ------------------------------------ # Use a descriptive name for the node: node.name: {{hostname}}
# Add custom attributes to the node: node.attr.rack: {{node_attr_rack}}
# ----------------------------------- Paths ------------------------------------ # Path to directory where to store the data (separate multiple locations by comma): path.data: {{path_data}}
# Path to log files: path.logs: {{elastic_log_dir}}
# ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # bootstrap.memory_lock: {{bootstrap_memory_lock}}
# ---------------------------------- Network ----------------------------------- # Set the bind address to a specific IP (IPv4 or IPv6): network.host: {{hostname}}
# Set a custom port for HTTP: http.port: {{elasticsearch_port}} transport.tcp.port: 9300
# ----------------------------------- Head Requires ----------------------------------- http.cors.enabled: {{http_cors_enabled}} http.cors.allow-origin: "{{http_cors_allow_origin}}" # --------------------------------- Discovery ---------------------------------- # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] discovery.zen.ping.unicast.hosts: {{discovery_zen_ping_unicast_hosts}}
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1): discovery.zen.minimum_master_nodes: {{discovery_zen_minimum_master_nodes}}
# ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # gateway.recover_after_nodes: {{gateway_recover_after_nodes}} # # For more information, consult the gateway module documentation. # # ---------------------------------- Various 123----------------------------------- # # Require explicit names when deleting indices: # action.destructive_requires_name: {{action_destructive_requires_name}} {% if ping_timeout_default %}
<!-- Discovery --> <!--<property>--> <!--<name>discovery_zen_ping_unicast_hosts</name>--> <!--<value></value>--> <!--<description>Pass an initial list of hosts to perform discovery when new node is started</description>--> <!--</property>-->
<!--<property>--> <!--<name>discovery_zen_minimum_master_nodes</name>--> <!--<value>1</value>--> <!--<description>Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1)</description>--> <!--</property>-->
<!-- Head Requires --> <property> <name>http_cors_enabled</name> <display-name>Http cors enabled</display-name> <value>true</value> <description>Whether to support cross-domain</description> <value-attributes> <overridable>false</overridable> <type>value-list</type> <entries> <entry> <value>true</value> <label>ON</label> </entry> <entry> <value>false</value> <label>OFF</label> </entry> </entries> <selection-cardinality>1</selection-cardinality> </value-attributes> </property>
<property> <name>http_cors_allow_origin</name> <display-name>Http cors allow origin</display-name> <value>*</value> <description>Allow cross-domain, default is "*", indicating support for all domain names.</description> </property>
<!-- Gateway --> <property> <name>gateway_recover_after_nodes</name> <display-name>Gateway recover after nodes</display-name> <value>1</value> <description>Allow Initialization Recovery after N Nodes Start</description> <final>true</final> <value-attributes> <type>int</type> <minimum>0</minimum> <maximum>6</maximum> <increment-step>1</increment-step> </value-attributes> </property>
<!-- Various --> <property> <name>node_max_local_storage_nodes</name> <display-name>Node max local storage nodes</display-name> <value>1</value> <description>Set the number of elasticsearch nodes that a machine can run, usually using the default of 1. </description> <final>true</final> <value-attributes> <type>int</type> <minimum>0</minimum> <maximum>6</maximum> <increment-step>1</increment-step> </value-attributes> <on-ambari-upgradeadd="true"/> </property>
<property> <name>action_destructive_requires_name</name> <display-name>Action destructive requires name</display-name> <value>false</value> <description>When deleting an index, do you need to specify a name explicitly? When the value is false, it can be deleted by regular or _all. </description> <value-attributes> <overridable>false</overridable> <type>value-list</type> <entries> <entry> <value>true</value> <label>ON</label> </entry> <entry> <value>false</value> <label>OFF</label> </entry> </entries> <selection-cardinality>1</selection-cardinality> </value-attributes> <on-ambari-upgradeadd="true"/> </property>
<property> <name>es.head.http.policy</name> <value>HTTP_ONLY</value> <description> This configures the HTTP endpoint for Elasticsearch Head Daemons.The following values are supported: - HTTP_ONLY : Service is provided only on http - HTTPS_ONLY : Service is provided only on https </description> </property> <property> <name>zookeeper.session.timeout</name> <value>90000</value> <description>ZooKeeper session timeout. ZooKeeper session timeout in milliseconds. It is used in two different ways. First, this value is used in the ZK client that HBase uses to connect to the ensemble. It is also used by HBase when it starts a ZK server and it is passed as the 'maxSessionTimeout'. See http://hadoop.apache.org/zookeeper/docs/current/zookeeperProgrammers.html#ch_zkSessions. For example, if a HBase region server connects to a ZK ensemble that's also managed by HBase, then the session timeout will be the one specified by this configuration. But, a region server that connects to an ensemble managed with a different configuration will be subjected that ensemble's maxSessionTimeout. So, even though HBase might propose using 90 seconds, the ensemble can have a max timeout lower than this and it will take precedence. </description> <display-name>Zookeeper Session Timeout</display-name> <value-attributes> <type>int</type> <minimum>10000</minimum> <maximum>180000</maximum> <unit>milliseconds</unit> <increment-step>10000</increment-step> </value-attributes> <on-ambari-upgradeadd="false"/> </property> <property> <name>hbase.hregion.majorcompaction</name> <value>604800000</value> <description>Time between major compactions, expressed in milliseconds. Set to 0 to disable time-based automatic major compactions. User-requested and size-based major compactions will still run. This value is multiplied by hbase.hregion.majorcompaction.jitter to cause compaction to start at a somewhat-random time during a given window of time. The default value is 7 days, expressed in milliseconds. If major compactions are causing disruption in your environment, you can configure them to run at off-peak times for your deployment, or disable time-based major compactions by setting this parameter to 0, and run major compactions in a cron job or by another external mechanism. </description> <display-name>Major Compaction Interval</display-name> <value-attributes> <type>int</type> <minimum>0</minimum> <maximum>2592000000</maximum> <unit>milliseconds</unit> </value-attributes> <on-ambari-upgradeadd="false"/> </property> </configuration>
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configurationsupports_adding_forbidden="true">
<propertyrequire-input="true"> <name>kadmin.local.password</name> <display-name>admin password</display-name> <value/> <property-type>PASSWORD</property-type> <description>The password is used to add the kerberos database administrator</description> <value-attributes> <type>password</type> </value-attributes> </property>